Artificial Intelligence, zBlog
Why Vendor Lock-In Is the Real Hidden Cost of Enterprise AI Platforms
trantorindia | Updated: June 12, 2026

There is a bill you are not seeing when you evaluate enterprise AI platforms. It is not on the vendor’s pricing page. It is not in the pilot budget. It is not in the year-one ROI model. It shows up later — when the vendor raises API prices and you realize you have no practical alternative, when a model gets deprecated and your entire production workflow requires a rewrite, when an outage hits and the 47% of your business functions built on a single provider go dark simultaneously.
In June 2025, a major AI provider outage paralyzed thousands of enterprises that had built no fallback capability. The enterprises that survived with minimal disruption were not the ones with the best SLAs. They were the ones that had designed model-agnostic systems. The ones with architecture that treated any single AI provider as replaceable. Everyone else spent days in crisis mode, discovering in the worst possible circumstances how deeply embedded their single-vendor dependency had become.
A 2026 Zapier enterprise survey found that 81% of enterprise leaders are concerned about AI vendor dependency. The same survey found that only 6% believe they could switch their primary AI provider without material operational disruption. That gap — between the 81% who know the risk is real and the 6% who have done anything about it — is the state of enterprise AI architecture right now.
Vendor lock-in is the most underestimated operational risk in enterprise AI in 2026. Not because it is hidden — most technology leaders understand it conceptually. But because the migration from understanding the risk to actually designing against it requires architectural decisions that conflict with the speed at which enterprises have deployed AI. The cost of fixing a lock-in problem after the fact is measured in months of engineering time and millions of dollars. The cost of designing against it upfront is measured in weeks of architectural thinking.
Why AI Vendor Lock-In Is Different From Traditional Software Lock-In
Enterprise technology leaders have managed vendor lock-in for decades. The CRM that became impossible to replace because too much institutional data lived in proprietary formats. The ERP that became the center of gravity for every connected system. These are familiar problems with established management strategies.
AI vendor lock-in is categorically different in ways that make traditional lock-in management strategies insufficient.
The dependency is not just functional — it is cognitive. When your teams build workflows around a specific model’s behavior — its tone, its reasoning patterns, its failure modes — they develop implicit knowledge that does not transfer to a different model. Switching from GPT-5 to Claude or from Claude to Gemini is not a configuration change. It requires revalidating every prompt, retuning every system prompt, rebuilding every evaluation benchmark. The cognitive and workflow debt is invisible in any cost model that looks only at API rates.
The pricing is not contractually stable. Traditional enterprise software contracts include price escalation caps and termination provisions. AI API pricing can change with minimal notice. Azure OpenAI pricing changes in early 2025 effectively doubled AI spend for some enterprise customers who had built usage-based cost models into their AI business cases — and found those models invalidated by pricing shifts they had no contractual protection against. Source: Pixels & Pulse February 2026.
The model deprecation cycle is faster than traditional software. Enterprise software products have multi-year lifecycle commitments. AI models deprecate in months. When a model is deprecated, production workflows built on it require testing, validation, and redevelopment against the replacement — often at significant engineering cost and always at business continuity risk.
The agentic AI layer amplifies every dependency. As of April 2026, only 7–8% of organizations have integrated cross-agent governance, while over 75% are concerned about vendor and API dependency risks. When AI moves from text generation to autonomous action — executing workflows, calling external APIs, making decisions — the blast radius of a single-vendor failure expands from “the chatbot is down” to “business-critical processes have stopped.” Source: FifthRow May 2026; Kai Waehner April 2026.
The 6 Hidden Cost Categories of AI Vendor Lock-In
The visible costs of an AI platform — subscription fees, per-token pricing, seat licenses — are the smallest part of the total cost exposure for an organization that has not designed against lock-in. The hidden costs are substantially larger, and they are not visible until the decision to stay or leave has already been made.
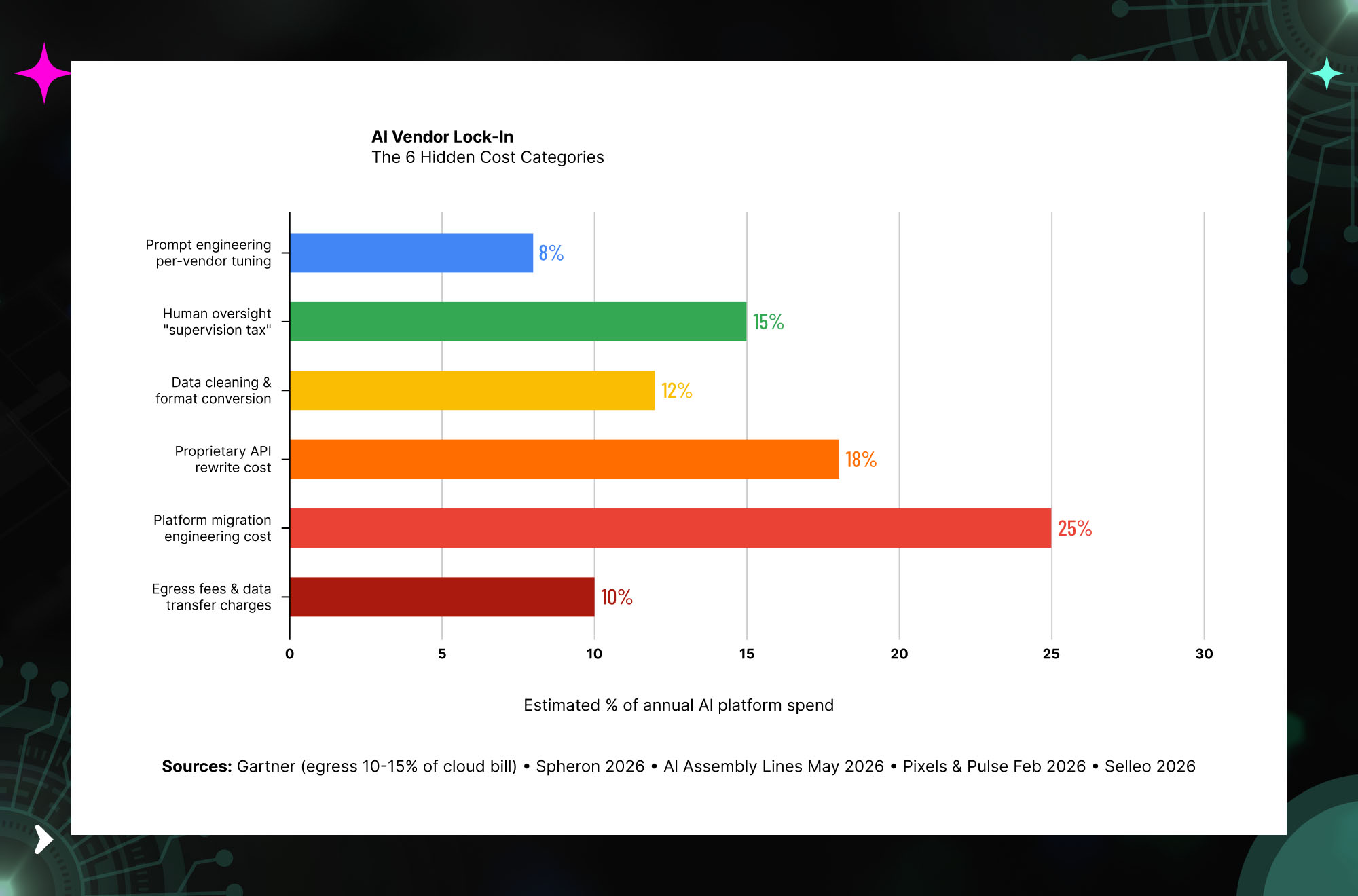
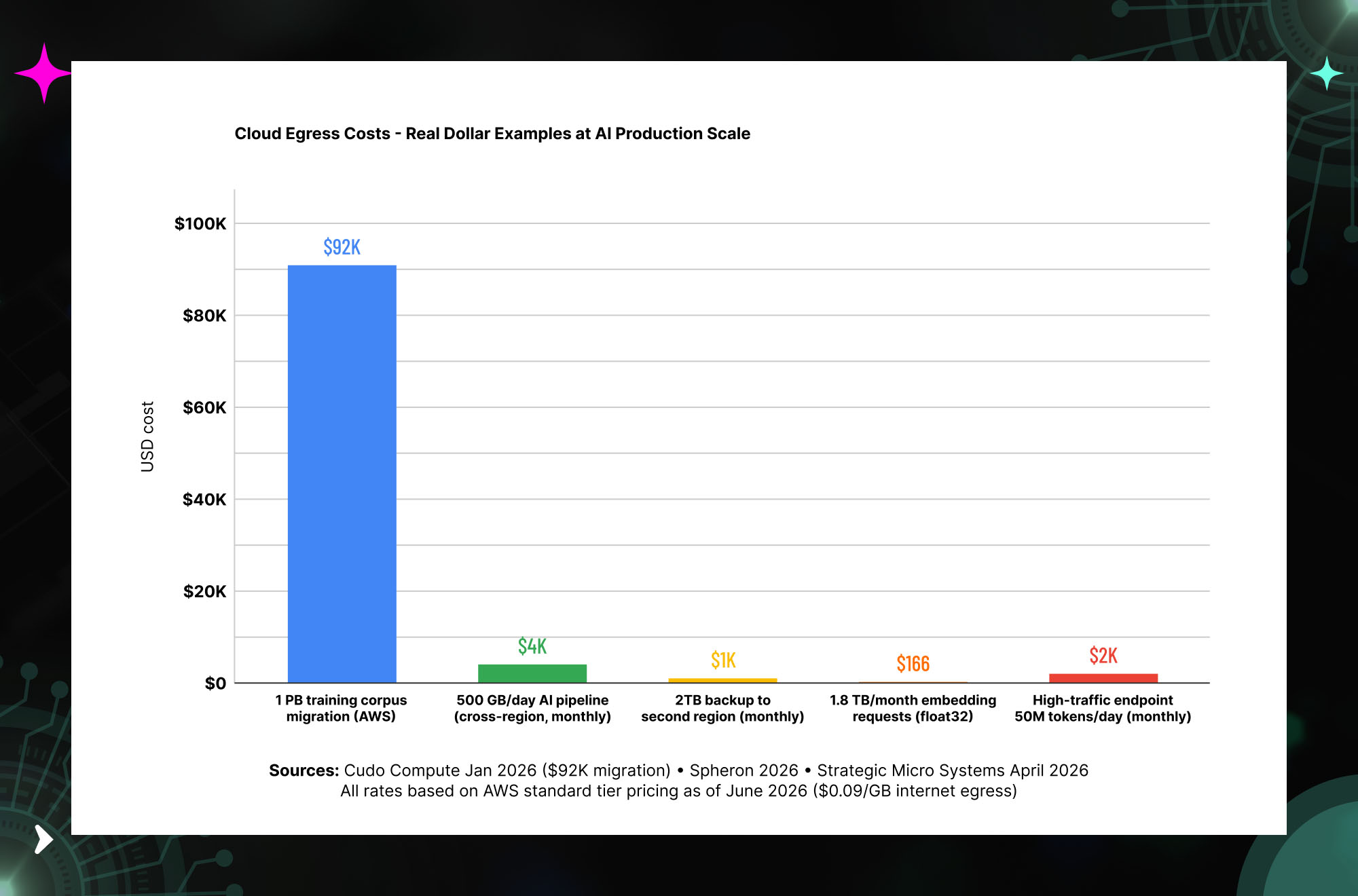
Hidden Cost 1: Egress Fees and Data Transfer Charges
Gartner estimates that data egress fees consume 10–15% of a typical enterprise cloud bill. IDC puts the figure at approximately 6% of total storage spend even for well-managed teams. At AI production scale, these numbers become concrete very quickly.
Moving a 1 PB training corpus out of AWS costs approximately $92,000 in egress alone — before accounting for the engineering time to execute the migration. A 500 GB per day AI pipeline running cross-region costs $4,500 per month in transfer fees. A 2 TB backup to a second region runs $1,200 per month. At the model embedding layer, returning 1,000 float32 embeddings per batch request sends 6 MB per response — at 100,000 embedding requests per day, that is 1.8 TB per month in egress (Spheron, 2026). Source: Cudo Compute January 2026.
EGRESS NOTE: The EU Data Act (effective 2025) forced the hyperscalers to waive egress fees for customers fully exiting their cloud. Inside the cloud, providers compete on compute and storage prices and quietly leave egress alone because it creates lock-in. Do not plan around fee cuts from regulatory pressure. Plan around your own architecture. Source: Strategic Micro Systems, April 2026.
Cloud Egress Costs — Real Dollar Examples at AI Production Scale
Hidden Cost 2: Platform Migration Engineering Cost
When vendor lock-in forces a move, the engineering cost is the largest single line item. Kellton’s analysis found that 57% of IT leaders spent more than $1 million on platform migrations in the previous year — often triggered by pricing changes, service degradation, or model deprecations. The UK Cabinet Office estimated that overreliance on a single cloud provider could cost public bodies £894 million. Basecamp projected $7 million in savings over five years specifically from avoiding cloud lock-in. Source: Buzzclan February 2026.
The migration cost is not primarily the new platform setup. It is the code rewrites — every API call that uses a proprietary SDK, every prompt that was tuned for a specific model’s behavior, every evaluation framework calibrated against a specific model’s output distribution. When the destination model behaves differently from the source model, the rework extends from infrastructure to every layer of the application stack.
Hidden Cost 3: Proprietary API and Format Coupling
Every proprietary AI API introduces coupling debt. A codebase built against OpenAI’s Python SDK requires meaningful rewrites to migrate to Anthropic’s SDK or Google’s Vertex AI client. A workflow built around Azure OpenAI’s enterprise features requires architectural changes to move to AWS Bedrock. The coupling is not just at the API call layer — it extends to authentication patterns, error handling, token counting, context management, and the specific ways each provider handles streaming, function calling, and agentic workflows.
The practical cost: when Azure OpenAI changed its pricing structure in early 2025, enterprises with deep proprietary API coupling faced a binary choice between absorbing a 100%+ cost increase or executing a migration that their architecture was not designed to make easy. Most absorbed the cost increase. Source: Pixels & Pulse February 2026.
Hidden Cost 4: Data Format and Training Data Lock-In
Fine-tuned models and custom embeddings represent significant investments of data labeling, compute, and validation effort. Most enterprise AI platforms store fine-tuning data and model weights in proprietary formats. Exporting, converting, and revalidating that investment on a different platform requires data cleaning and format conversion work that typically adds 10–30% to migration costs. Source: Pixels & Pulse February 2026.
Vector databases compound this problem. Embeddings generated by one model are not compatible with embeddings from a different model — not because of format, but because of semantic structure. A vector store built on OpenAI text-embedding-ada-002 embeddings cannot be migrated to a Cohere or Anthropic embedding model without recomputing every embedding. At scale, this is not a configuration task. It is a significant engineering project.
Hidden Cost 5: The Human Oversight Supervision Tax
Enterprise AI deployments have a hidden labor cost that vendor pricing never mentions. The supervision tax — the engineer and domain expert hours spent reviewing, correcting, and validating AI outputs — is real, significant, and scales with the volume of AI-assisted work. One real-world estimate: an agent team automation project required a senior engineer to spend 20 hours per week babysitting agentic workflows, fixing bad logic, and finding missed dependencies. At $200,000 annual salary, that is $8,000 per month in supervision cost that no vendor pricing sheet acknowledges. Source: Pixels & Pulse February 2026.
This cost is lock-in relevant because different AI models require different supervision levels for the same task. A model optimized for cost efficiency may require 3x the human oversight budget of a more capable but more expensive model. Without the ability to route workloads to the right model for each task — which requires a model-agnostic architecture — enterprises pay the supervision tax on every task regardless of whether it warranted the lower-capability model.
Hidden Cost 6: Regulatory and Compliance Exposure
The regulatory landscape for enterprise AI in 2026 requires risk assessments, audit trails, and explainability for AI systems used in regulated decisions. When your AI infrastructure is tied to a vendor’s black-box ecosystem, meeting these requirements becomes structurally harder. The EU AI Act requires conformity assessments, human oversight mechanisms, and explainability of AI-influenced decisions. Organizations using proprietary AI systems face challenges demonstrating compliance when the model’s decision-making process is opaque.
Data sovereignty is a compounding factor. When Meta declined to release its new LLM in the EU due to regulatory uncertainty, enterprises whose AI strategies depended on that model had no fallback. LLM-agnostic architectures maintained operations. Source: Swfte AI 2026.
The Awareness-Preparedness Gap — What the Data Shows
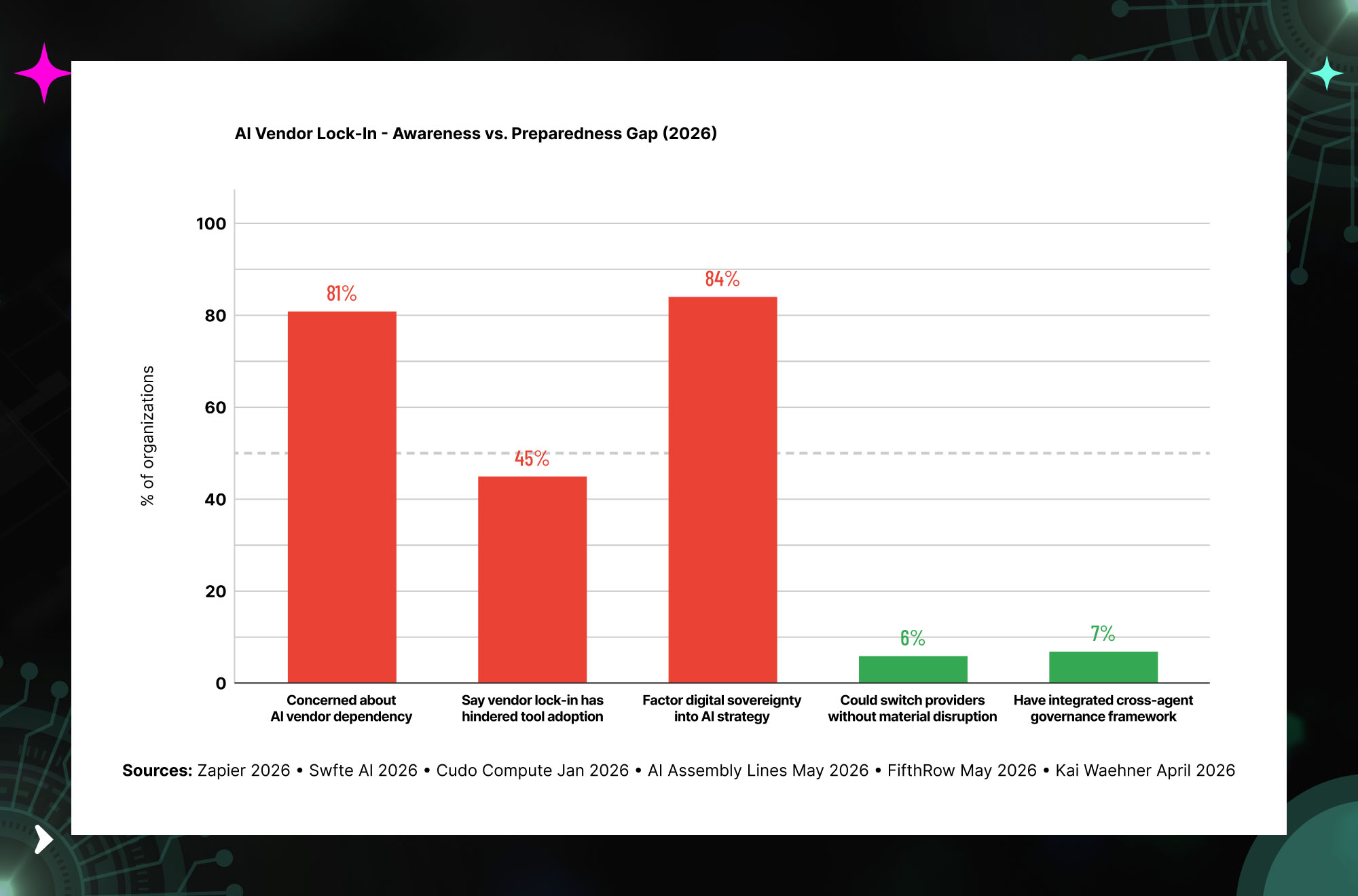
The survey data across multiple 2026 research sources tells a consistent and sobering story: enterprise awareness of AI vendor lock-in risk is high, but preparedness to address it is extremely low. 81% of enterprise leaders are concerned about AI vendor dependency. 45% say vendor lock-in has already hindered their ability to adopt better tools. 84% factor digital sovereignty into their AI strategies. And yet only 6% believe they could switch their primary AI provider without material disruption, and only 7–8% have integrated cross-agent governance.
This pattern — high awareness, low action — reflects the architectural decisions that enterprises made during the AI deployment acceleration of 2023–2025. Speed of deployment was the priority. The organizations that built the most comprehensive AI capabilities fastest were often the same organizations that built the deepest vendor dependencies. The bill for that speed comes due when a vendor changes pricing, deprecates a model, or experiences a service disruption.
Real-World Lock-In Incidents — What Actually Happened
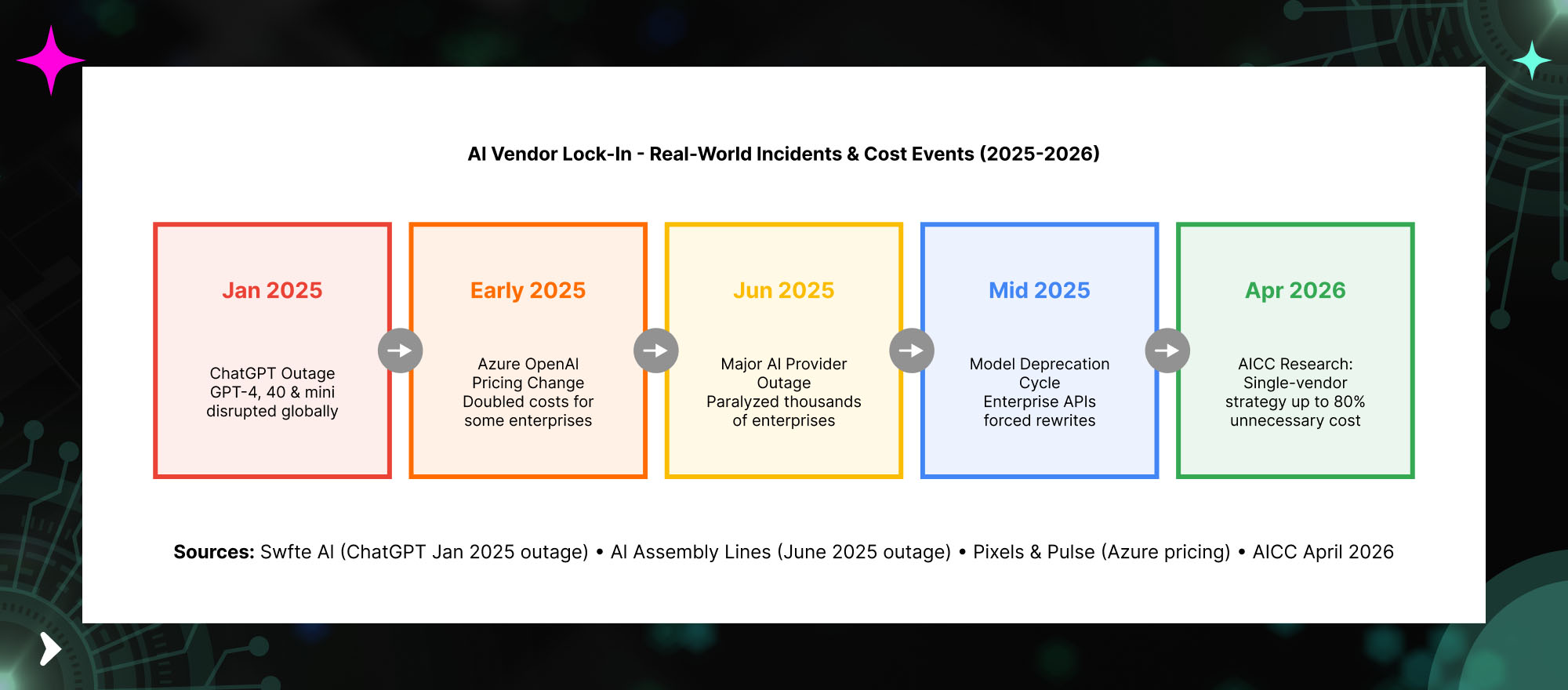
January 2025 — ChatGPT outage disrupted GPT-4, GPT-4o, and mini models globally. Organizations that had built model-agnostic systems maintained operations. Organizations dependent on a single provider experienced customer-facing disruptions. The outage was hours long — enough to materially affect time-sensitive business processes. Swfte AI documented this as the first major public demonstration of the business continuity risk of single-vendor AI dependency.
Early 2025 — Azure OpenAI pricing changes effectively doubled AI spend for some enterprise customers. Enterprises that had built usage-based cost models into their AI business cases found those models invalidated. Those with model-agnostic routing were able to shift workloads to lower-cost alternatives. Those without that capability absorbed the increase or initiated expensive migrations. Source: Pixels & Pulse February 2026.
June 2025 — A major AI provider outage paralyzed thousands of enterprises. Kai Waehner’s analysis documented how organizations that had built customer service, internal operations, and decision workflows on a single AI provider had no fallback. 47% of enterprise leaders in the Zapier 2026 survey say a key business function would stop if their primary AI vendor went down. In June 2025, this was not hypothetical — it happened.
Mid-2025 — Model deprecation cycles forced enterprise API rewrites. As model generations turn over faster than traditional software lifecycles, enterprises built on specific model versions face recurring rewrite cycles. Each deprecation requires testing, validation, and redevelopment against the replacement model — costs that were not in any original AI investment model and that compound with each new model generation.
RISK ALERT: 47% of enterprise leaders say a key business function would stop if their primary AI vendor went down, yet only 6% believe they could switch providers without material disruption. This is not a theoretical risk. The June 2025 outage demonstrated that these failures happen at real scale, with real business impact. The question is not whether your primary AI vendor will experience a disruption. It is whether your architecture can survive it when it does. Source: Zapier 2026 Enterprise Survey.
AI Vendor Lock-In Risk Matrix — Understanding Your Exposure by Platform Type

Lock-in risk is not uniform across the AI platform landscape. Understanding which category of AI investment creates which type of lock-in exposure is the first step toward designing an architecture that manages risk intelligently.
The Lock-In Mitigation Framework — Building AI Architecture That Protects You
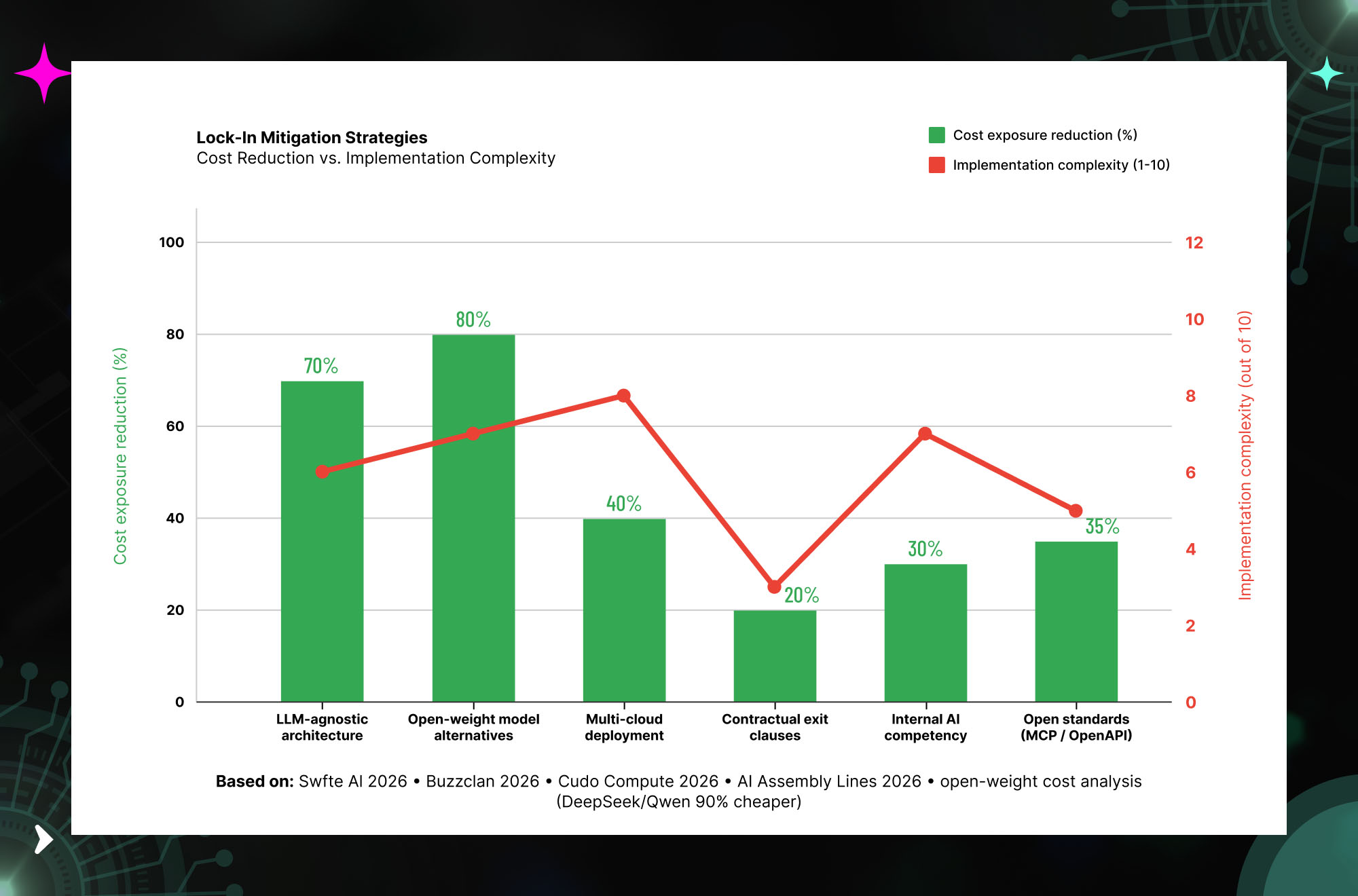
Strategy 1: LLM-Agnostic Architecture (Highest Cost Reduction, Medium Complexity)
The most impactful architectural decision you can make against lock-in is building LLM-agnostic application layers. Every API call to a specific model provider goes through an abstraction layer — a router that can direct requests to any model meeting the task requirements. When a model’s pricing changes or a service goes down, the router simply redirects to the next-best option. The application layer sees no change.
This is not complex architecture. It is a design discipline: never let a proprietary SDK call appear directly in application code. Use an abstraction library (LiteLLM, the AI SDK, or a custom router) that normalizes the interface across providers. The engineering investment is weeks, not months. The protection it provides is permanent.
PRACTICAL EXAMPLE: Organizations that used LLM-agnostic routing during the January 2025 ChatGPT outage and the June 2025 major AI provider outage maintained continuous operations. Those that had built direct API integrations experienced disruption. The architectural difference was not sophistication — it was the presence or absence of a provider-abstraction layer. Source: Swfte AI 2026.
Strategy 2: Open-Weight Model Integration (Highest Absolute Cost Reduction)
The most significant cost reduction available in AI infrastructure in 2026 is deploying open-weight models for appropriate workloads. Open models like DeepSeek V3.1 and Qwen3 achieve inferencing costs up to 90% lower than proprietary alternatives when self-hosted or used via third-party hosting. Source: Swfte AI 2026.
The practical framework: segment your AI workloads by the combination of sensitivity, complexity, and consequence. High-sensitivity workloads involving proprietary data belong on self-hosted open models where no data leaves your infrastructure. High-volume, lower-complexity workloads (classification, extraction, summarization) are the best fit for cost-optimized open models. High-consequence, high-complexity reasoning tasks that justify frontier model pricing remain on proprietary APIs — but now represent a smaller fraction of total AI spend.
Strategy 3: Contractual Protection — Negotiating Exit Provisions
Most enterprises accept vendor AI agreements without negotiating the exit provisions. This is a significant oversight that commercial legal teams should address in every enterprise AI agreement. Negotiate explicit contractual commitments on data portability (your data in standard, exportable formats), data egress fee caps at contract termination, transition assistance obligations (vendor-provided migration support), and rate escalation limits for multi-year commitments.
Some enterprises have successfully included “exit tax” caps in their agreements — provisions that explicitly limit egress fees and migration costs if the enterprise decides to leave. These provisions are negotiable, especially for significant ACV commitments. The legal team needs to be involved in AI platform selection, not just the technical evaluation. Source: Southeast Asia Digital Sovereignty 2026 analysis.
Strategy 4: Multi-Model Deployment with Intelligent Routing
Rather than choosing between AI providers, mature enterprise AI architectures in 2026 route workloads to the optimal model for each task based on cost, latency, quality, and data sensitivity requirements. A high-volume internal summarization task might route to a cost-efficient open model. A customer-facing response requiring GPT-5’s instruction-following might route to Azure OpenAI. A complex reasoning task might route to Claude Opus.
This routing architecture, combined with the LLM-agnostic application layer described above, creates a portfolio approach to AI infrastructure that manages cost, capability, and risk simultaneously. When any single vendor changes pricing or experiences an outage, the routing layer shifts workloads to the next-best alternative automatically.
Strategy 5: Build Internal AI Competency
The most durable protection against vendor lock-in is institutional knowledge. Organizations whose AI capability lives primarily in vendor relationships rather than internal teams cannot evaluate alternatives, cannot execute migrations, and cannot design against future lock-in risks because they lack the technical judgment to recognize them.
Invest in internal prompt engineering expertise, model evaluation capability, MLOps skills, and AI architecture judgment. These capabilities allow your teams to evaluate emerging alternatives objectively, execute migrations when needed, and design future AI systems with appropriate abstraction from the start.
Frequently Asked Questions About AI Vendor Lock-In
Conclusion: Sovereignty Is the Real Enterprise AI Strategy
The question enterprises are asking — “which AI platform should we standardize on?” — is the wrong question. It assumes that standardization is the right strategy. The data in 2026 suggests that standardization on a single AI vendor is an operational and financial risk, not a simplification.
The right question is: “How do we build AI capability that is durable, portable, and not hostage to any single vendor’s pricing decisions, deprecation cycles, or service availability?” The answer is architectural. LLM-agnostic application layers. Open-weight model deployments for appropriate workloads. Contractual exit provisions. Multi-model routing. Internal institutional knowledge that does not live in a vendor relationship.
81% of enterprise leaders are concerned about AI vendor dependency. The 6% who have done something about it are building a durable competitive advantage that the others are not — not because their AI is more capable, but because their AI infrastructure is more resilient. That resilience will matter increasingly as the model market continues to evolve, pricing structures continue to shift, and the regulatory environment continues to tighten around data sovereignty and AI accountability.
At Trantor (trantorinc.com), we help enterprises design AI infrastructure that delivers capability without creating the vendor dependencies that turn into strategic liabilities. Our architecture practice covers LLM-agnostic application design, open-weight model deployment and evaluation, multi-cloud AI infrastructure, contractual risk assessment for AI agreements, and the governance frameworks that maintain enterprise AI sovereignty as the market evolves. Whether you are evaluating your current vendor lock-in exposure, designing a new AI platform architecture from scratch, or executing a migration from an over-concentrated single-vendor deployment — that is the work we are built for.











