Artificial Intelligence, zBlog
Machine Learning Challenges in Enterprise: Why 87% of ML Projects Never Reach Production

The machine learning challenges facing enterprise teams in 2026 are not the same ones covered in most textbooks. Overfitting, imbalanced data, and feature selection are real technical problems, but they are solvable with standard techniques that any competent ML engineer knows. The machine learning challenges that actually end careers and kill budgets are organizational, operational, and infrastructural, and the statistics behind them are sobering enough that every enterprise team planning an ML initiative should understand them before writing a single line of model code.
According to Gartner, 87 percent of machine learning projects never make it to production. McKinsey research found that enterprises spend up to 80 percent of their total ML project time on data preparation before any model training even begins. IDC estimated that organizations wasted $96 billion on failed AI and ML projects in 2025 alone. These are not niche findings from a single study. They represent a consistent pattern across research from Gartner, McKinsey, IDC, and the Anaconda State of Data Science reports over several years.
This guide covers the machine learning challenges that the data shows actually matter, organized by where they appear in the ML pipeline, what they cost when ignored, and what the evidence says actually works to address them. The goal is not to discourage investment in machine learning. It is to help enterprise teams enter with an accurate picture of what they are signing up for, so they can be among the 13 percent of ML initiatives that actually reach production and stay there.
The most important reframe for any enterprise thinking about machine learning challenges: the hardest problems are rarely the algorithms. They are the data, the infrastructure, the organizational change management, and the ongoing costs of keeping models working after deployment. Teams that plan for these challenges from the start have dramatically better outcomes than those that discover them mid-project.
Where Machine Learning Projects Actually Fail in the Enterprise Pipeline
Before listing specific machine learning challenges, it helps to know where in the pipeline failures actually happen, because the distribution is not what most teams expect. Most ML failure discussions focus on model performance issues during training, but the data tells a different story.
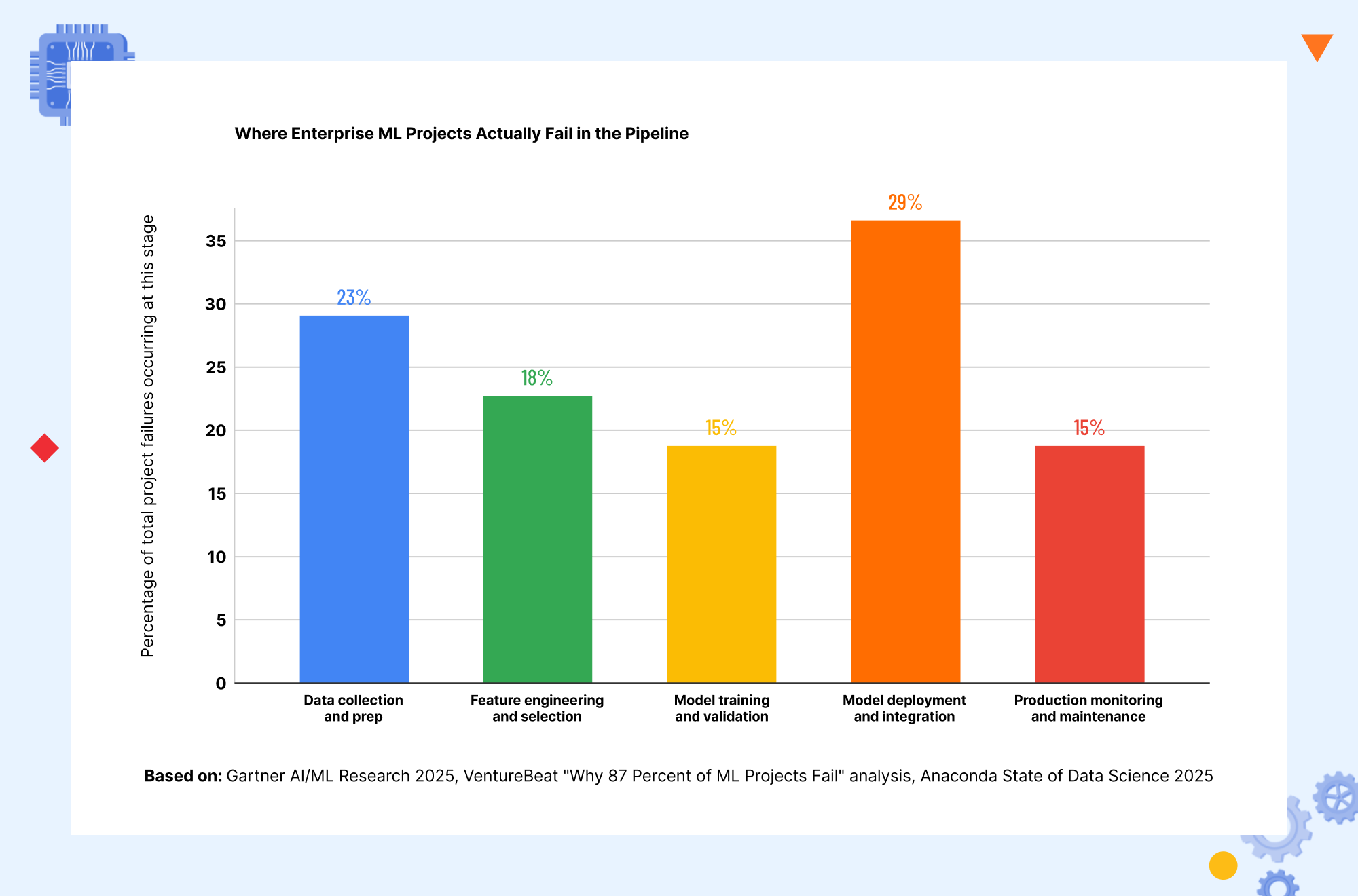
Deployment and integration account for the largest share of enterprise ML failures, at roughly 29 percent of failed projects. This reflects a structural problem that many ML teams discover too late: building a model that performs well in a Jupyter notebook and deploying that model into a production system that handles real traffic, integrates with existing databases and APIs, meets latency requirements, and operates reliably over time are fundamentally different engineering challenges. Data preparation and collection failures account for 23 percent, feature engineering failures for 18 percent, and model training validation failures for 15 percent. Production monitoring failures account for the remaining 15 percent, where models that initially worked correctly gradually degrade as the data they see in production drifts from the data they were trained on.
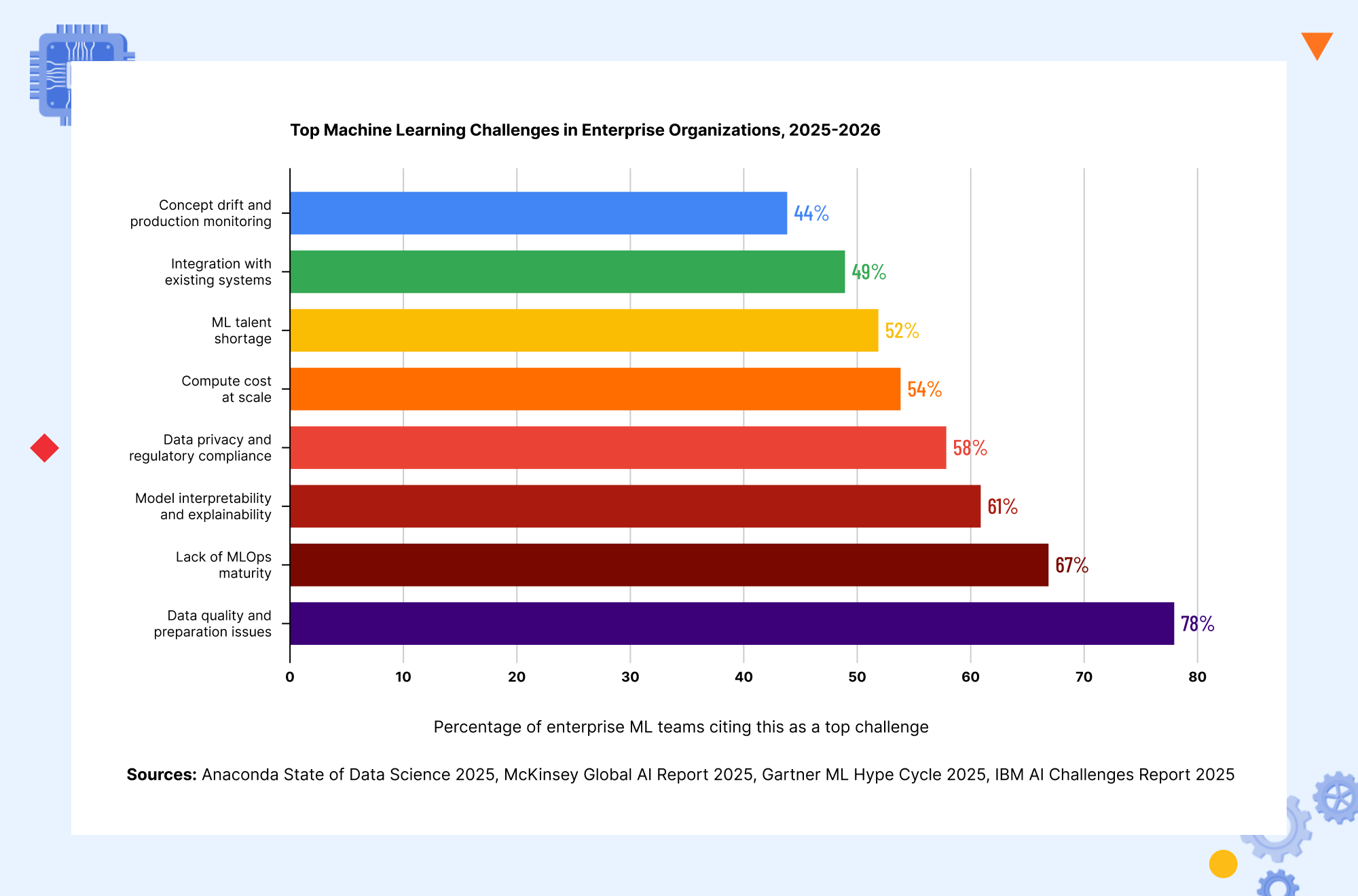
The 8 Most Significant Machine Learning Challenges in 2026
The following machine learning challenges are ordered by how frequently they are cited as primary failure causes across the research landscape, not by technical complexity. The hardest problems on this list are organizational and operational, not algorithmic.
How Machine Learning Challenges Change as Organizations Mature
One of the most useful frameworks for understanding machine learning challenges is recognizing that the hardest problems change depending on where an organization is in its ML maturity journey. An organization piloting its first ML use case faces a completely different set of machine learning challenges than one managing dozens of models in production.
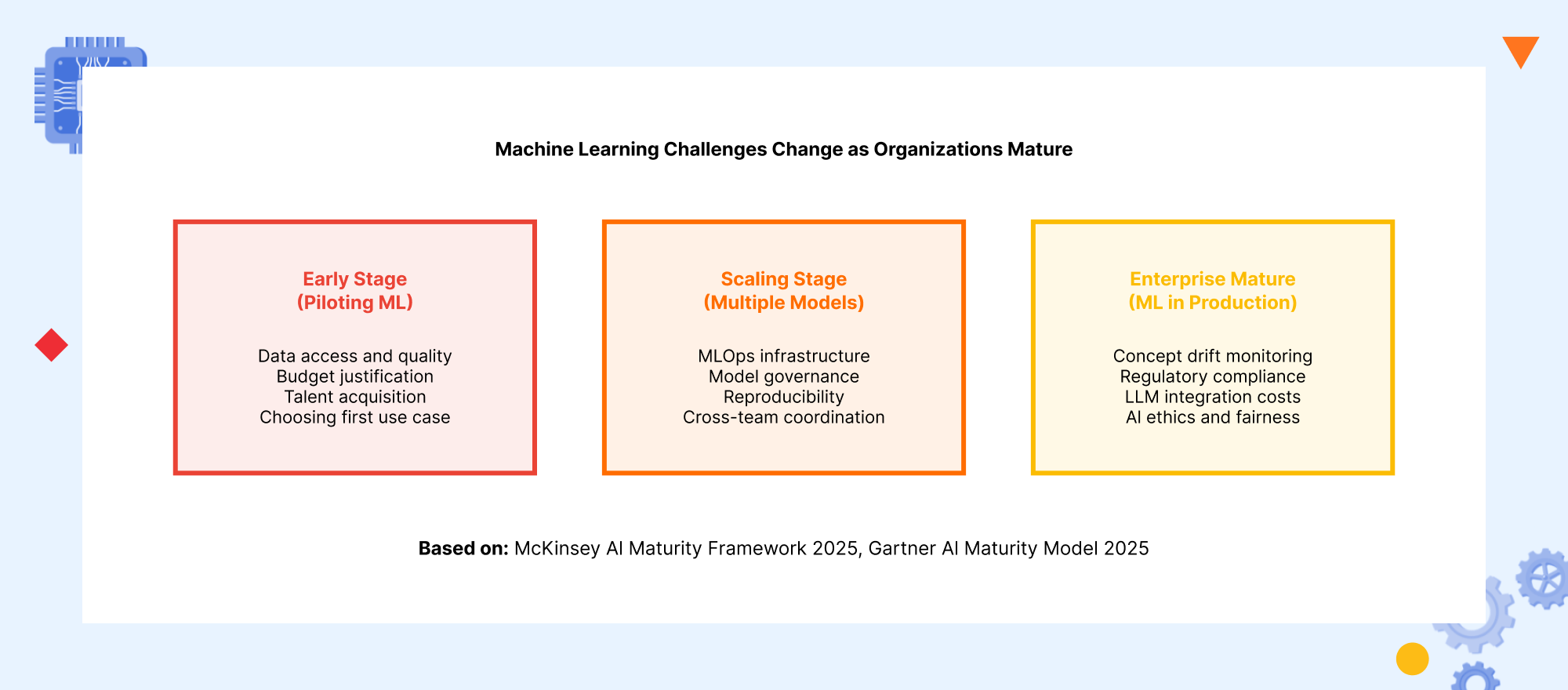
Early-stage organizations typically face machine learning challenges related to data access, building the business case for investment, recruiting initial talent, and choosing the right first use case. The right first ML use case is almost always one where the problem is well-defined, the training data already exists and is reasonably clean, and the business value of a correct prediction is high and measurable. Getting the first project right builds organizational credibility for the investment required by subsequent projects.
Scaling-stage organizations that have proven ML value in one area and are expanding to multiple use cases face machine learning challenges around MLOps infrastructure, model governance, reproducibility, and cross-team coordination. The practices that worked when one team owned one model break down when multiple teams own multiple models with different data dependencies, retraining schedules, and monitoring requirements.
Mature enterprise ML organizations managing many models in production face machine learning challenges around concept drift monitoring at scale, regulatory compliance as the regulatory environment tightens, LLM integration costs, and AI ethics and fairness auditing. These organizations also face the challenge of technical debt in their ML systems: models and pipelines built quickly in earlier phases that now require significant investment to meet current engineering standards.
The Time Allocation Problem Behind Most Machine Learning Challenges
One of the most clarifying pieces of data about machine learning challenges comes from comparing how ML teams actually spend their time with how they expected to spend it at the project’s outset.
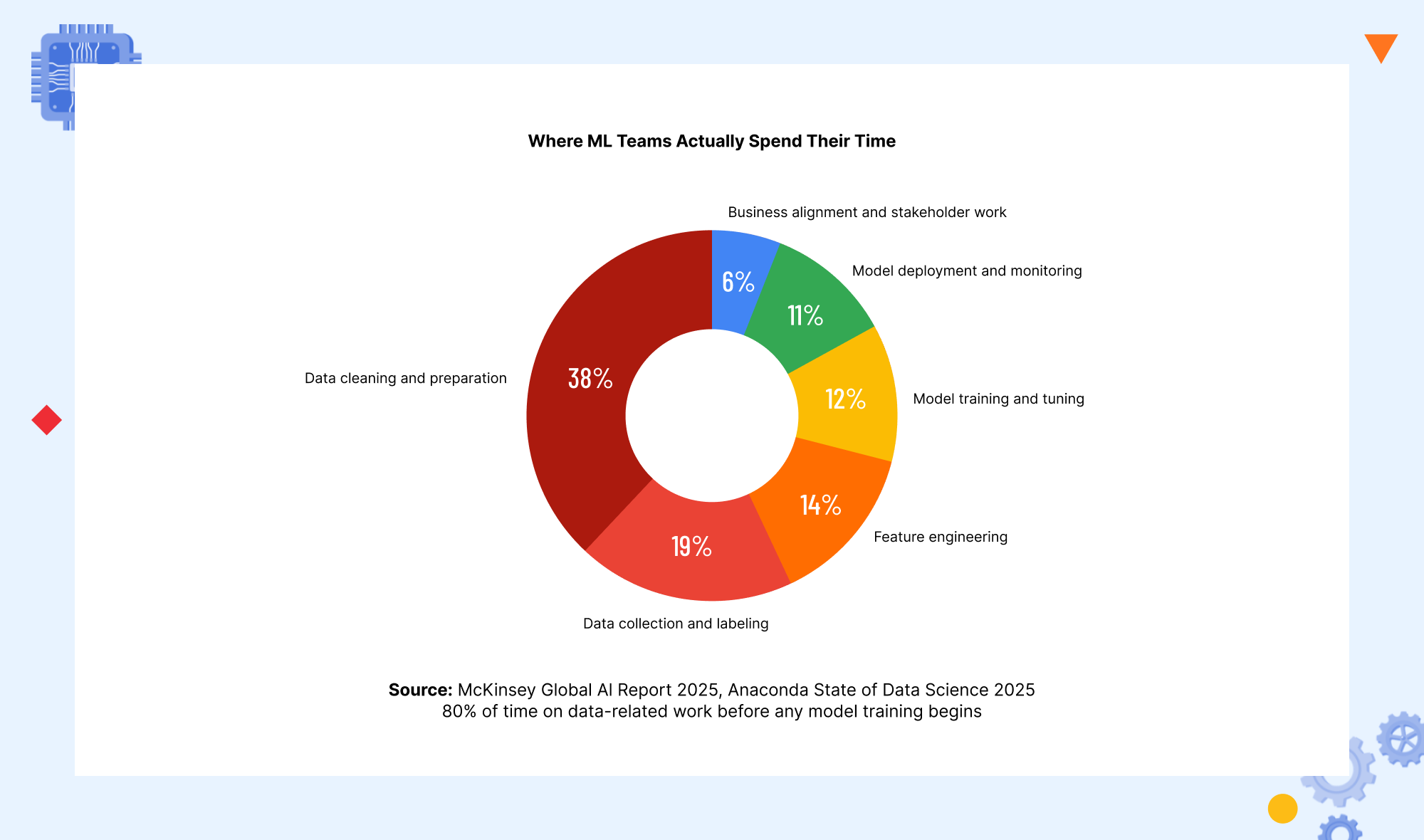
Data cleaning and preparation consume 38 percent of total ML project time. Data collection and labeling consume another 19 percent. Feature engineering takes 14 percent. Combined, these three data-related activities consume 71 percent of total ML project time before a single model training run begins. Model training and tuning account for 12 percent, production deployment and monitoring for 11 percent, and business alignment and stakeholder work for the remaining 6 percent.
This time distribution explains why data quality is consistently the most cited machine learning challenge in every enterprise survey: it is consuming the most time, and it is the work that most ML teams were not hired to do and did not budget for adequately. It also explains why the machine learning challenges that most tutorials focus on, choosing the right algorithm, tuning hyperparameters, and avoiding overfitting, represent only a small fraction of where ML project time and energy actually go.
PLANNING IMPLICATION: If your ML project budget and timeline are built around the assumption that most effort goes into model development, your plan is likely to fail for the same reason 87 percent of ML projects do. Build your project timeline assuming that roughly 70 percent of effort goes into data-related work. If that assumption turns out to be wrong and your data is cleaner than average, you will have delivered ahead of schedule. If the assumption is correct, you will not have discovered a budget crisis three months in.
Frequently Asked Questions About Machine Learning Challenges
Machine Learning Challenges Are Solvable, but Only When They Are Planned For
The machine learning challenges covered in this guide are not reasons to avoid investing in ML. The organizations that have solved them, that make it into the 13 percent of ML projects that reach and stay in production, have not found fundamentally different algorithms or discovered some secret technique. They have planned for the actual distribution of effort that ML projects require, invested in data quality and MLOps infrastructure before they needed it urgently, and treated model deployment and monitoring as engineering problems with the same rigor they apply to other production systems.
The most useful thing an enterprise team can do before starting an ML initiative is to read the failure statistics honestly. 87 percent failure to reach production. 80 percent of the time is spent on data work. $96 billion wasted annually. These numbers are not arguments against machine learning. They are arguments for going in with an accurate plan rather than an optimistic one, because the gap between those two things is where most ML initiatives get lost.
At Trantor, we help enterprise organizations navigate machine learning challenges from initial use-case selection through production deployment to ongoing monitoring. We bring both the ML engineering depth and the organizational experience to help teams plan realistically, build the right infrastructure, and reach the 13 percent of ML projects that actually deliver production value. If you are planning an ML initiative or troubleshooting one that has stalled, we are ready to help.
Explore Trantor’s Machine Learning and AI Services: Machine Learning











