Digital Transformation, zBlog
Data Warehousing – Definition, Types, Process, Use Cases, Components

Every major cloud provider has a page that defines a data warehouse. AWS has one. So does Google Cloud, IBM, Oracle, SAP, and Microsoft. They are all reasonably good, and they all share one structural limitation. Each one is, understandably, framed to lead you toward that provider’s own data warehouse product.
What those pages tend to underserve is the harder, more useful question: which type of data warehouse, which deployment model, and which ingestion pattern actually fits your organization’s data, regulatory environment, and existing technology stack. That is the question this guide on data warehouse types is built to answer, written from the position of a consultancy that implements data warehouse systems across multiple cloud and on-premises platforms rather than selling just one of them.
This guide defines data warehousing clearly and quickly first, because that grounding matters. But the bulk of the content focuses on the comparisons and decisions that determine whether a data warehouse project actually succeeds: how a data warehouse differs from a database and a data lake, which of the several data warehouse types fits your situation, how on-premises, cloud, and hybrid deployment really compare, and when to use ETL versus ELT.
For us at Trantor, data warehousing is not just a piece of technology. It is part of a broader data strategy that connects people, processes, and platforms. The goal of this guide on data warehouse types is to help you make that strategic decision with a clear head, before you commit to a specific vendor’s framing of the problem.
What Is a Data Warehouse? A Quick, Clear Definition
A data warehouse is a centralized repository that collects, integrates, and stores large volumes of current and historical data from multiple sources, organized specifically to support analytics, reporting, and decision making rather than day to day transactions. Data typically flows in from operational systems such as CRM, ERP, point of sale, and marketing platforms, gets cleaned and standardized, and is then queried by analysts, dashboards, and increasingly by AI and machine learning systems.
That is the short version. The reference definition for what makes a true data warehouse, used consistently by Oracle, IBM, and most enterprise architecture teams, comes from William Inmon, widely considered the father of the data warehouse, who identified four characteristics that distinguish a true data warehouse from an ordinary database.
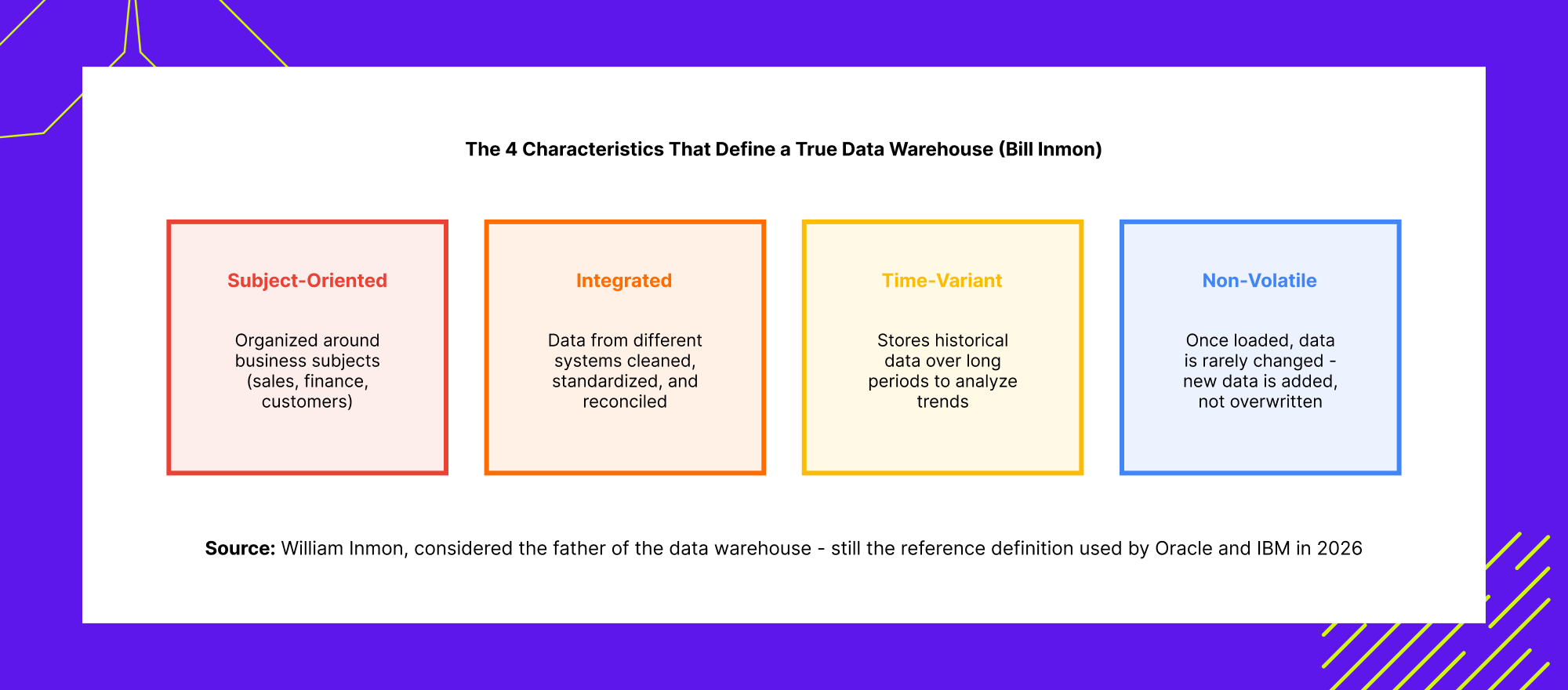
Subject oriented means data is organized around business subjects like sales, finance, or customers rather than around individual source applications. Integrated means data from different systems is cleaned, standardized, and reconciled so the same customer or product means the same thing everywhere in the data warehouse. Time variant means the data warehouse holds historical data over long periods specifically to support trend analysis. Non volatile means once data is loaded, it is rarely changed or deleted. New data accumulates rather than overwriting the record.
Data Warehouse vs. Database vs. Data Lake: The Comparison That Actually Determines Your Architecture
This is the question we hear most often from clients, and it is the one vendor glossary pages tend to answer thinly, because each vendor wants to sell you their own data warehouse product specifically, not help you decide whether you need a data warehouse, a data lake, or both. Here is the honest, vendor-neutral comparison.
Data Warehouse vs. Database vs. Data Lake – The Decission That Matters The Most
| Database | Data Warehouse | Data Lake | |
|---|---|---|---|
| Primary purpose | Day-to-day transactions | Analytics & decision-making | Raw storage at scale |
| Optimized for | Fast writes & lookups | Read-heavy aggregated queries | Cheap, flexible ingestion |
| Data structure | Highly normalized | Star/snowflake schemas | Raw, often unstructured |
| Typical users | Applications, end users | Analysts, BI tools | Data scientists, ML engineers |
| Risk if misused | N/A — built for this | Becomes slow under scale | Becomes a “data swamp” |
| Database | |
|---|---|
| Primary purpose | Day-to-day transactions |
| Optimized for | Fast writes & lookups |
| Data structure | Highly normalized |
| Typical users | Applications, end users |
| Risk if misused | N/A — built for this |
| Data Warehouse | |
|---|---|
| Primary purpose | Analytics & decision-making |
| Optimized for | Read-heavy aggregated queries |
| Data structure | Star/snowflake schemas |
| Typical users | Analysts, BI tools |
| Risk if misused | Becomes slow under scale |
| Data Lake | |
|---|---|
| Primary purpose | Raw storage at scale |
| Optimized for | Cheap, flexible ingestion |
| Data structure | Raw, often unstructured |
| Typical users | Data scientists, ML engineers |
| Risk if misused | Becomes a “data swamp” |
Operational databases focus on day to day transactions: creating orders, updating customer records, processing payments. They are optimized for fast writes and lookups, not for scanning millions of rows of history. If you run a query that joins five years of sales data against a live operational database, you will likely slow down the system that your business runs on in real time.
Data warehouses focus on analytics and decision making: answering questions, spotting patterns, powering dashboards. A data warehouse is optimized for read heavy, aggregated queries and complex joins, typically using columnar storage and dimensional modeling (star and snowflake schemas) specifically so that scanning years of history is fast rather than disruptive.
Data lakes store raw, often unstructured data such as logs, events, files, and documents at scale, typically in cheap object storage. They are excellent for data science, machine learning, and experimentation precisely because they do not force structure on data upfront. The honest tradeoff is that without deliberate modeling and governance, a data lake can become what practitioners call a “data swamp,” technically searchable but practically unusable.
WHERE THIS IS HEADING:
Increasingly, organizations are adopting lakehouse architectures, platforms like Databricks, Snowflake, and BigQuery using open table formats, that bring the governance and performance discipline of a data warehouse into a data lake environment, enabling both traditional BI and advanced AI workloads on one common foundation. If you are starting a new data platform in 2026, this convergence is worth evaluating before assuming you need a separate data warehouse and data lake.
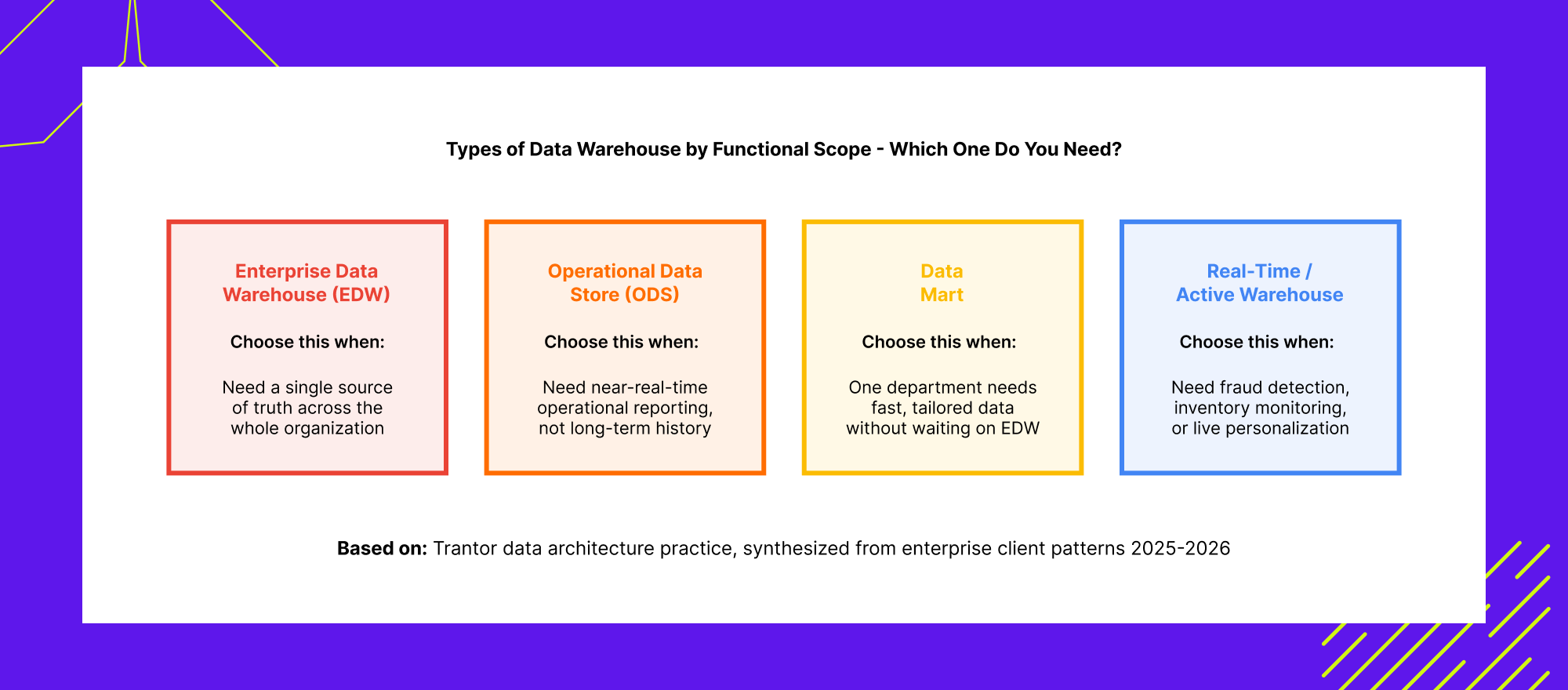
Types of Data Warehouse by Functional Scope: Which One Do You Actually Need?
This is one of the few data warehouse related queries where impressions are still growing rather than declining, and it is exactly the kind of question a vendor-neutral guide can answer more usefully than a single cloud provider’s page, because the right answer genuinely depends on your organization’s structure, not on which platform you choose.
On-Premises vs. Cloud vs. Hybrid Data Warehouse Deployment
Functional scope is one decision axis for choosing among data warehouse types. Deployment model is the other, and it is frequently driven by factors outside the data team’s control: existing infrastructure investment, regulatory data residency requirements, and the organization’s overall cloud strategy.
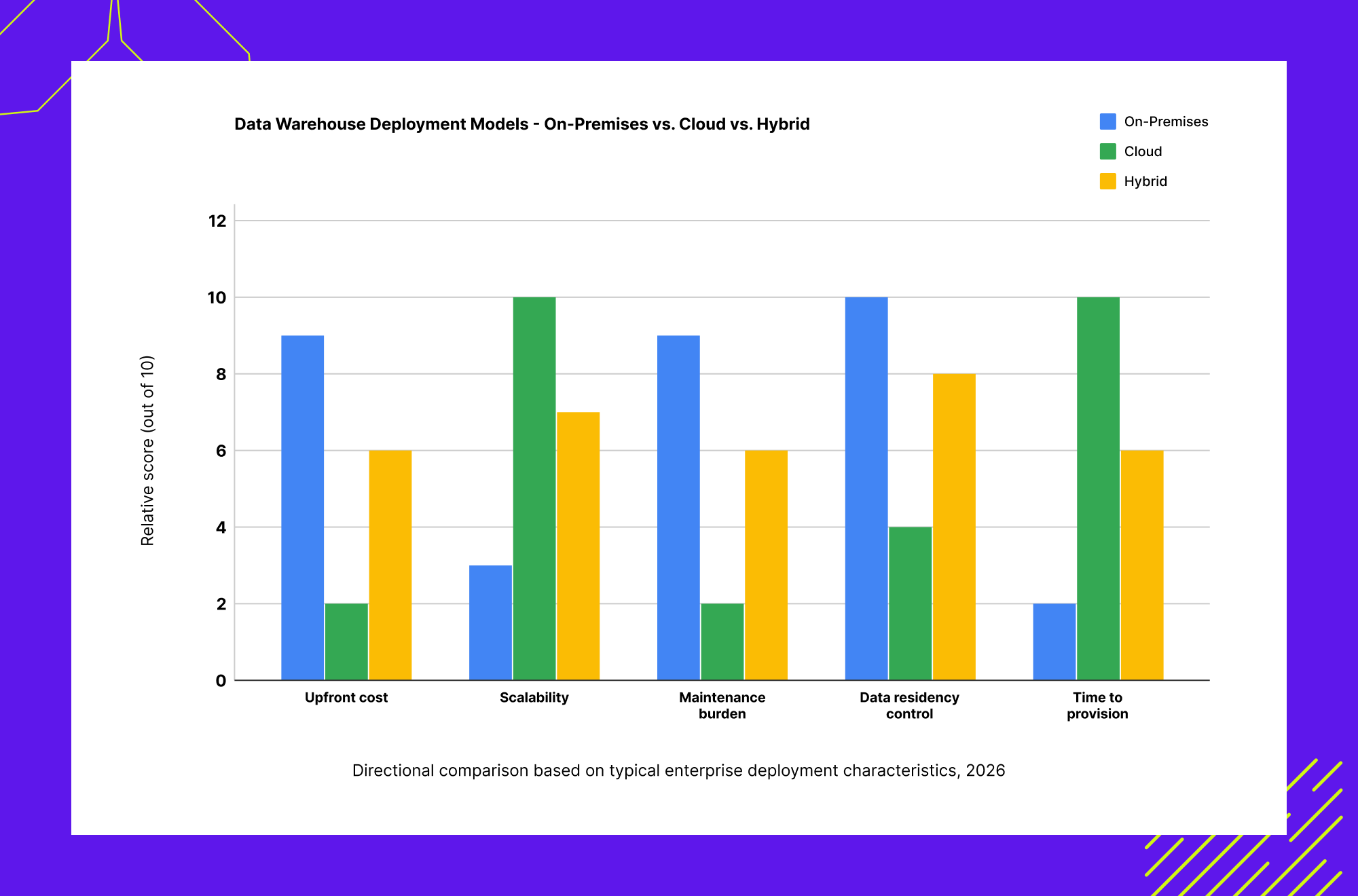
On-premises data warehouses run in the organization’s own data center on physical or virtual servers, giving full control over hardware and security at the cost of higher upfront investment and ongoing maintenance burden. This remains common in industries with strict data residency rules or substantial existing legacy infrastructure that has not yet been justified for migration.
Cloud data warehouses are fully or largely managed offerings from providers such as Snowflake, Amazon Redshift, Google BigQuery, and Azure Synapse. They provide elastic compute and storage, usage based pricing, and rapid provisioning. For most organizations scaling analytics in 2026 without an existing large on-premises investment, a cloud data warehouse is the default starting point.
Hybrid data warehouses combine on-premises and cloud environments, often deliberately, during a multi year modernization journey. Data may be replicated or federated across both environments with secure connectivity. This is the realistic middle path for large enterprises that cannot move everything to the cloud at once, whether due to contractual lock in, regulatory timing, or workloads that genuinely need to stay on-premises.
ETL vs. ELT: Choosing the Right Data Warehousing Ingestion Pattern
Once you know what type of data warehouse and which deployment model you need, the next concrete decision is how data actually gets into it. This is a genuinely technical choice with real cost and architecture implications, not just terminology.
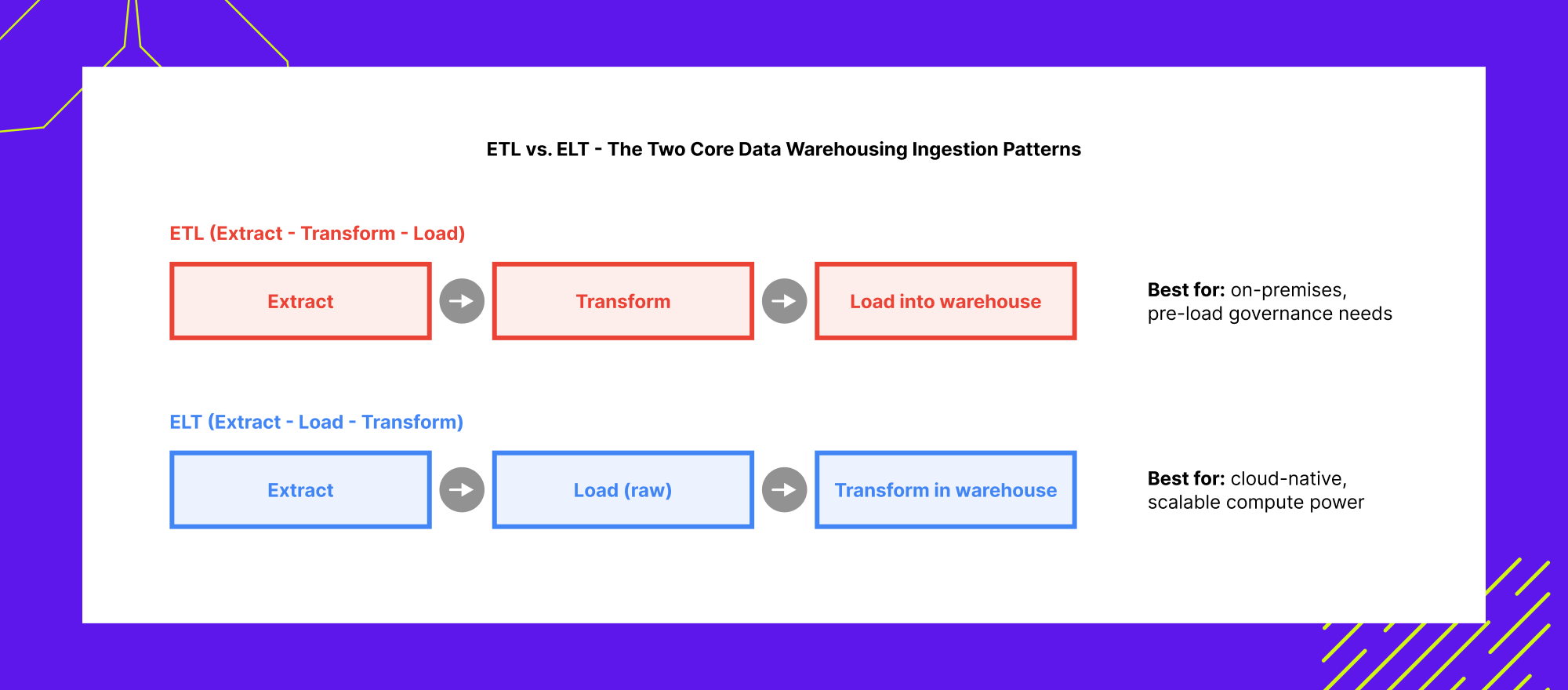
ETL (Extract, Transform, Load) extracts data from source systems, transforms it using integration tools, and only then loads the cleaned result into the data warehouse. This pattern suits on-premises architectures and situations where transformations must happen, for compliance or data quality reasons, before data ever reaches the main store.
ELT (Extract, Load, Transform) loads data into the data warehouse quickly in near raw form, then transforms it there using the warehouse’s own compute power. This is the dominant pattern in cloud data warehousing, where the separation of storage and compute, combined with elastic scaling, makes transforming data inside the warehouse both fast and cost effective.
Modern data warehousing stacks increasingly combine both: batch ELT for bulk historical loads, alongside streaming ingestion through tools like Kafka or cloud native streaming services for the real time or near real time feeds that an active data warehouse, covered above, depends on.
The Core Components of a Modern Data Warehouse
Regardless of type or deployment model, a properly built data warehouse is a coordinated system of components, not just a big database.
Data sources: The operational applications, SaaS platforms, machine and IoT data, and external feeds where data originates. Good data warehousing design starts with a clear inventory of which systems are the authoritative system of record for each data domain.
Ingestion and integration layer: The ETL or ELT pipelines, increasingly combining batch and streaming methods, that move and prepare data for the data warehouse.
Central storage: Where integrated, modeled data lives, typically using star or snowflake schemas, columnar storage formats, and partitioning strategies designed for fast analytical queries rather than transactional speed.
Metadata, catalog, and semantic layer: The connective tissue that helps people trust and find data: technical metadata such as table structures and lineage, business metadata such as KPI definitions and ownership, and a semantic layer where business users work with friendly terms like Net Revenue instead of raw table names.
Analytics, BI, and access tools: The visible layer of the data warehouse for most users: BI dashboards in tools like Power BI, Tableau, or Looker, SQL and notebook access for analysts and data scientists, and APIs feeding downstream applications and machine learning workflows.
Frequently Asked Questions About Data Warehouse Types and Architecture
Choosing the Right Data Warehouse Architecture: The Real Takeaway
The definition of a data warehouse is, by now, settled and consistent across every major vendor and the technical literature: a centralized, integrated, subject oriented, time variant, non volatile repository built for analytics rather than transactions. That part is not where organizations actually struggle.
Where data warehouse projects succeed or stall is in the decisions this guide has focused on: which type of data warehouse actually matches your organizational structure, whether on-premises, cloud, or hybrid deployment fits your regulatory and infrastructure reality, and whether ETL or ELT, or a deliberate combination of both, fits your data volume and governance requirements. Those decisions benefit from a vendor-neutral perspective precisely because no single cloud provider’s documentation is positioned to tell you when their own data warehouse platform is not the right fit.
At Trantor, data warehousing is part of a broader data strategy that connects people, processes, and platforms, not a single product decision. We help organizations evaluate data warehouse type, deployment model, and ingestion architecture against their actual data, regulatory environment, and existing technology stack, whether that means designing a first data warehouse from scratch or modernizing a legacy one. If you are weighing these data warehouse decisions for your own organization, we are ready to help you make them with a clear head.











