Artificial Intelligence, zBlog
How to Build an LLM
trantorindia | Updated: November 26, 2025

From Objectives to Deployment: A Comprehensive Enterprise Roadmap
Enterprises today are turning to large-language models (LLMs) to unlock transformative capabilities: conversational agents, automated content, domain-specific support, deeper analytics. But how do you build an LLM—especially one aligned with enterprise requirements, scaled appropriately, and sustainably deployed? This guide lays out a clear, structured path, along with key considerations, risks and best practices, so your organisation can treat “build an LLM” not as a vague ambition, but a realistic engineering and business roadmap.
What Is an LLM?
Before we dive into how to build one, let’s start with the fundamentals.
An LLM (Large Language Model) is a type of artificial intelligence model that can understand, generate, and manipulate human language. It’s trained on massive amounts of text data and uses deep learning (specifically, transformer architecture) to predict and generate text based on the input it receives.
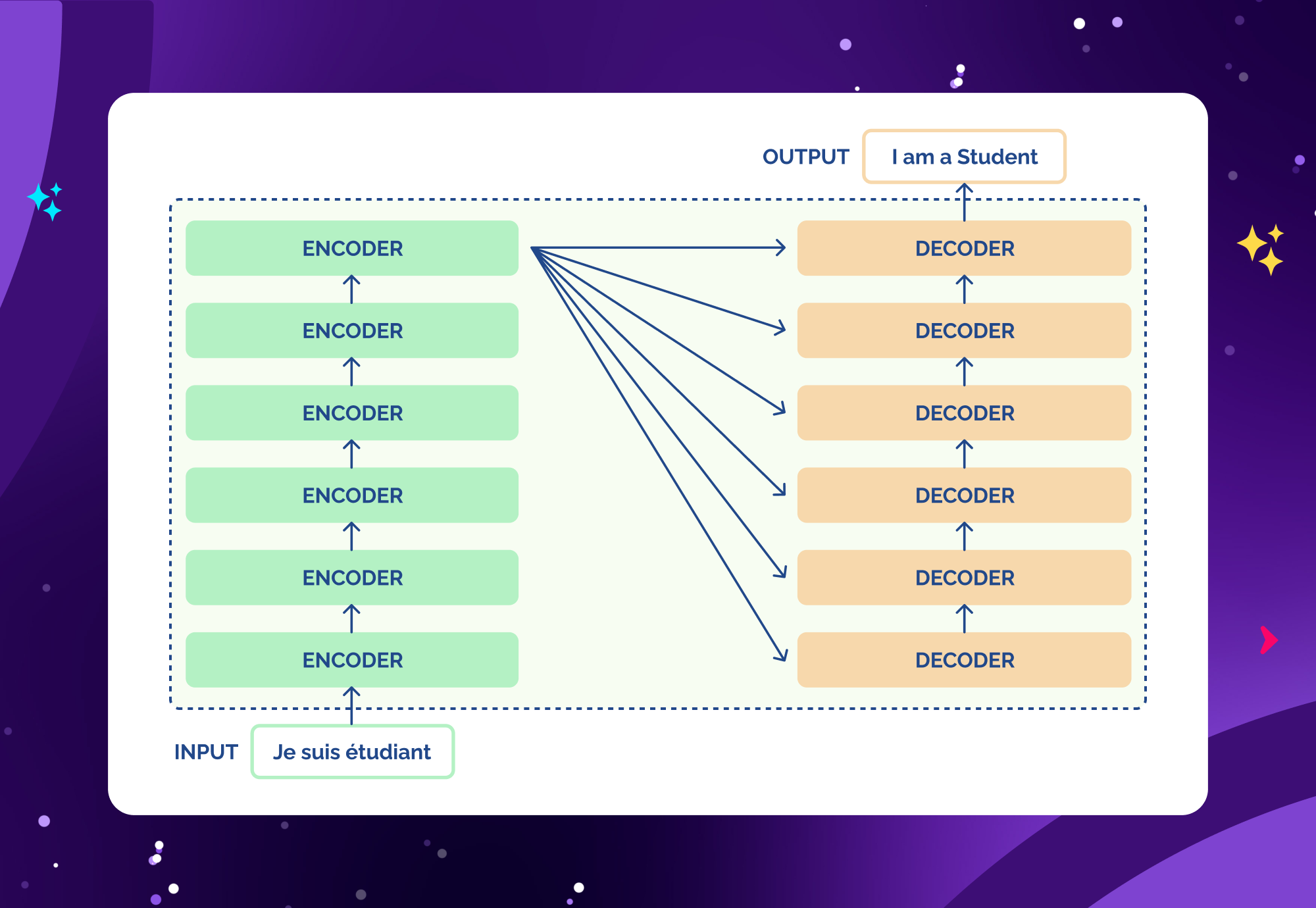
Think of it as the engine that powers modern AI applications like ChatGPT, Bard, Claude, or LLaMA. But unlike simple chatbots, an LLM isn’t programmed with pre-written rules, it learns the patterns, structures, and relationships in language itself.
How LLMs Work In Simple Terms
At the core of an LLM lies a transformer neural network — an architecture that understands context through “attention.” This means the model doesn’t just look at words individually, but also how they relate to each other across a sentence or paragraph.
- Input: The model receives text as tokens (numerical representations of words or word fragments).
- Computation: Through multiple layers of attention and learning, it predicts the most likely next token.
- Output: The tokens are decoded back into natural language.
This process happens millions (or billions) of times during training, allowing the model to “learn” syntax, semantics, and even reasoning patterns.
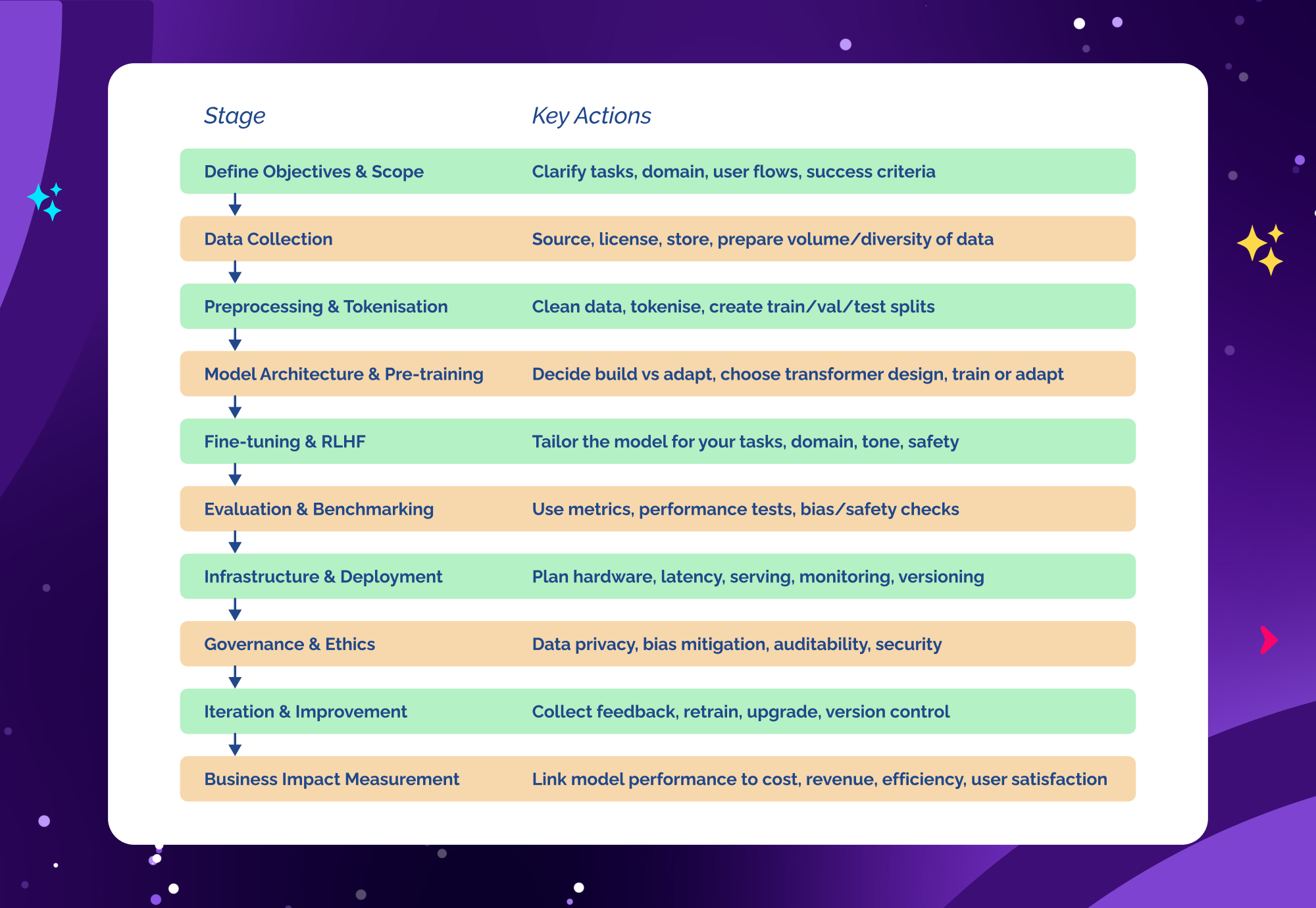
1. Define Your Objectives & Scope
Every successful LLM begins not with layers of neural nets but with clarity of purpose. Why are you building an LLM? What business value, what user-journey, what domain, what constraints?
Why start here
According to the guide from Multimodal Dev, one of the first steps in building a large language model is to “define objectives” and have a clear problem statement for what the model should do. Similarly, in an education context, organisations emphasise defining scope before plunging into data or compute.
Key questions to ask
- What tasks will the model perform? (e.g., question-answering in your domain, summarisation, code generation, support chat)
- What domain or vertical is in scope? (legal, healthcare, manufacturing, finance)
- What quality and performance levels are required? (accuracy, latency, throughput)
- What data will it ingest and produce? What languages, modalities?
- What constraints apply? (privacy/data governance, cost/compute budget, regulatory/compliance, deployment environment)
- How will the model integrate into systems or user flows? (embedding into an app, chatbot, partner API)
- How will you measure success? (benchmarks, KPIs, business metrics)
Having crisp answers to these questions aligns all stakeholders—engineering, data science, business, legal—to the same target and sets up the rest of your build for efficiency and focus.
2. Data Collection – The Fuel of the Model

Once objectives are clear, the next major pillar is your data strategy. The quality, volume, variety and relevance of your dataset will deeply shape the eventual model.
What constitutes “data” for an LLM
Per the Google ML introduction: “A language model is … a machine learning model that aims to predict and generate plausible language.” To do that effectively, inherently the model needs tokens from a wide variety of contexts (words, sentences, paragraphs) that represent the kind of language it will handle. So data = large collections of text (or if multimodal, text + images/audio) that reflect your domain and use-cases.
Key stages in data collection
- Source identification: Determine which sources you need (public web text, domain-specific documents, internal knowledge bases, user logs, transcripts).
- Licensing & rights: Ensure you have permissions, and that you remove or anonymise sensitive or personal data to meet privacy/compliance.
- Volume & diversity: The more tokens and the more diverse the contexts, the more potential for generalisation. As Stanford’s “AI demystified” note puts it: “The goal is to gather enough data to cover various topics, writing styles, and contexts…”
- Quality & relevance: Just volume isn’t enough. Data must be clean, aligned with your domain, representative of the tasks you will run.
- Data labelling / metadata: While pre-training LLMs often uses self-supervised data, you’ll still need some labelled data for fine-tuning or evaluation.
- Storage & management: Large datasets require scalable pipelines, versioning, governance (who can see/access what), ETL strategy.
Enterprise-specific tip
If you’re a company with internal knowledge (white papers, manuals, chat logs, CRM transcripts), you can leverage in-domain data to train/fine-tune a model that’s specialised rather than generic. This gives you differentiation. But it also raises governance issues: ensure you handle PII, document consent, and ensure data lineage.
3. Data Preprocessing & Tokenisation
Raw data is rarely ready for model ingestion. Before training begins, you must transform, clean, normalise, and tokenise.
Why this stage matters
The review from Elastic (Understanding large language models) emphasises how LLMs are composed of embedding layers, attention mechanisms, feed-forward layers and more. The encoder doesn’t consume raw web text—it consumes tokens, embeddings. If you feed noisy, inconsistent input, you degrade model performance.
Steps & best practices
- Clean & normalise: Remove duplicates, irrelevant content (spam, boilerplate), fix encoding issues, unify language, remove non-text noise.
- Filtering: Remove hateful, toxic, copyrighted or irrelevant content depending on your policy.
- Tokenisation: Choose your vocabulary (Byte-Pair Encoding (BPE) or WordPiece or other tokeniser). Tokenise consistent across training and inference.
- Chunking/context windows: Determine how you slice text into sequences (e.g., 512 tokens per input). Larger context windows allow longer dependencies but also cost more.
- Metadata/annotations: For fine-tuning, you might label segments (e.g., “instruction / input / output” format).
- Shuffling / splitting: Separate training/validation/test sets to avoid bleed-through; ensure evaluation integrity.
Enterprise tip
Especially when using internal data, watch for sensitive information. It may be wise to anonymise or pseudonymise data, log data lineage, and ensure compliance before ingestion.
4. Model Architecture & Pre-training

Now you reach the heart of the LLM build: selecting or designing the model architecture, and proceeding with training. At this step, you can choose to build from scratch or fine-tune an existing model.
From scratch vs fine-tune
Guides outline three main approaches: build a large language model from scratch, fine-tune an existing pre-trained model, or customise an existing model. Building from scratch means: you decide architecture (number of layers, hidden size, attention heads), initialisation, train on your own large corpus. Fine-tuning means you start with a base model (open-source or commercial) and adapt to your domain.
Key architectural components
According to Elastic’s overview:
- Embedding layer: transforms tokens into vector space.
- Attention mechanism: enables the model to focus on different parts of input context.
- Feed-forward layers, residual connections, layer normalisation.
- Output layer: usually softmax over vocabulary to generate next token probabilities.
- If applicable: encoder-decoder (for translation) vs decoder-only (for generation) vs encoder-only (for classification).
Pre-training process
- You feed in large volumes of unsupervised data (text), often with tasks like next-token prediction or masked-token prediction.
- You update parameters via gradient descent until you’ve seen many billions/trillions of tokens.
- Compute cost is high; in practise, many organisations rely on cloud or HPC clusters.
Enterprise viewpoint
For a typical enterprise build, you may realistically opt for adaptation of existing models rather than training 100-billion-parameter models from scratch—since cost, compute, data all scale dramatically at that size. But if the build is mission-critical and you have budget/compute/data, scratch is viable (with partner-ecosystem like Trantor managing infrastructure).
5. Fine-Tuning, Instruction-Tuning & RLHF
Pre-training gives you a general-purpose model; next you tailor it for your tasks, your domain, your user needs.
What these steps involve
- Fine-tuning: Taking the pre-trained model and training on labelled or domain-specific data for your tasks.
- Instruction-tuning: Training the model to follow human instructions (“You are an assistant…”). Often uses prompt-instruction pairs.
- Reinforcement Learning with Human Feedback (RLHF): Where humans rank outputs from the model, and you use RL to optimise for preferred behaviour (less toxic, more helpful, aligned).
Why these matter
Pre-trained models are general. They might generate text that is irrelevant or misaligned with your domain or policy. Fine-tuning and RLHF allow you to:
- Align with business tone / brand guidelines
- Improve performance on domain-specific queries
- Filter or limit unwanted behaviours
- Adapt to user flows (for example, in enterprise chatbots, knowledge systems)
Example enterprise cases
- A financial services firm fine-tunes a base LLM so it understands regulatory language and compliance constraints.
- A manufacturing company uses RLHF to teach the model to generate procedural instructions following safety protocols.
- A media company uses instruction-tuning so the model writes in the brand tone when assisting content creators.
6. Evaluation & Benchmarking

How do you know your model is good? You must evaluate, benchmark, iterate.
Key evaluation aspects
- Perplexity: Common measure for language models — how “surprised” the model is by the test data.
- Task metrics: If you have a downstream task (e.g., Q&A accuracy, summarisation ROUGE, code generation pass rate), measure those.
- Bias, fairness, safety: According to recent research, LLMs can inherit biases and hallucinate; enterprises must test for these.
- Latency/throughput: How fast are responses? How many concurrent users?
- User experience: Conduct pilot tests with real users, capture feedback.
Benchmarking process
- Establish baseline performance (pre-finetune)
- Define target metrics (business KPIs)
- Run validation/test suites with held-out data
- Set up monitoring for drift once deployed (data distribution may change)
Enterprise tip
It’s wise to build a feedback loop: once deployed, collect logs of user interactions, failures/hits, and feed back into fine-tuning/iteration. This helps the model stay current and aligned with evolving business needs.
7. Infrastructure & Deployment
Once your model is ready, you need to deploy it in a production-safe, scalable way.
Infrastructure considerations
- Compute/Hardware: GPUs/TPUs for training; inference servers or edge hardware for deployment.
- Scalability: If many users access the model, you need autoscaling, load-balancing.
- Latency: Real-time use cases (chatbots) require fast response; batch use cases may tolerate delay.
- Memory/context window: Larger context windows increase compute/memory needs.
- Serving architecture: Model server, API layer, caching, state management if required.
- Monitoring & logging: Track usage, errors, latency, user satisfaction.
- Security and governance: Access controls, data encryption, audit logs, model-usage tracking.
Deployment patterns
- Cloud-based API: Serve model via cloud (AWS, GCP, Azure, etc).
- On-premises or hybrid: For regulated industries or sensitive data, you might deploy locally.
- Edge deployment: For latency-critical or offline use-cases, smaller quantised models may run on device.
- Model as a service inside enterprise: Wrap model behind internal APIs for other business systems to call.
Enterprise tip
Plan for versioning and roll-back: models change, you may need to revert to an earlier one if bugs emerge. Also plan for cost-management: inference cost can exceed training cost in many cases.
8. Governance, Compliance & Ethics

In an enterprise context, building an LLM isn’t just a technical exercise. It involves governance, risk mitigation, compliance and ongoing ethical management.
Key topics
- Data privacy & protection: If you used internal/customer data, ensure you adhered to data privacy laws (GDPR, CCPA, etc).
- Bias & fairness: Models may generate biased or unfair outputs; you should test and mitigate.
- Hallucinations & factuality: LLMs can confidently produce incorrect facts; you must design for that risk.
- Auditability & explainability: Enterprises often need to explain model decisions, track lineage, maintain logs.
- Security: Models may be exploited (prompt injection, back doors); ensure hardened deployment.
- Continuous monitoring: Over time, the world changes (data drift, new norms); governance must be ongoing.
- Ethical use cases: Define boundaries for model use (what it should/shouldn’t do) and enforce them.
Enterprise tip
Set up a model governance board or cross-functional team (legal, compliance, data science, business) to oversee policy, review model behaviour, handle escalation of issues.
9. Iteration & Continuous Improvement
Building an LLM is not a “train once and forget” operation. Continuous improvement is essential.
Why iteration matters
- Real-world usage reveals unforeseen issues, queries, failure modes.
- Business needs evolve; domain vocabulary changes, new tasks emerge.
- The underlying language world evolves (new slang, new context).
- Monitoring reveals drift, bias changes, performance degradation.
How to iterate
- Collect feedback: user logs, error reports, unanswered queries.
- Retrain/fine-tune periodically: new data, updated tasks, improved architecture.
- Benchmark new versions against previous ones before production rollout.
- Retract or roll back if major deficiencies are discovered.
- Maintain version control over data, model weights, configuration.
Enterprise tip
Treat your LLM deployment as a product rather than a one-off project. Assign owners, measure product KPIs (uptime, user satisfaction, cost per query), and invest continually.
10. Measure Business Impact

Finally, the goal of building an LLM is not just to have a fancy model, but to drive business value. So measure accordingly.
Metrics to track
- Cost savings: e.g., reduction in human support agents due to an LLM-powered chatbot.
- Revenue uplift: e.g., new services enabled by the model, or higher conversion through better engagement.
- Operational efficiency: fewer manual processes, faster turnaround, fewer errors.
- User satisfaction: improved NPS, reduced complaints.
- Risk reduction: fewer compliance incidents, fewer quality escapes.
Aligning to business KPIs
From the very beginning, when you defined your objectives (see Section 1), refer back to them. For example: if your objective is “reduce support resolution time by 30%”, ensure your LLM rollout has baseline metrics, and post-deployment you track and report progress.
Enterprise tip
Use dashboards and governance reports to update stakeholders regularly. When your LLM shows ROI, you unlock future investment for bigger initiatives.
Summary – The Enterprise LLM Build Checklist
Market Growth Trend
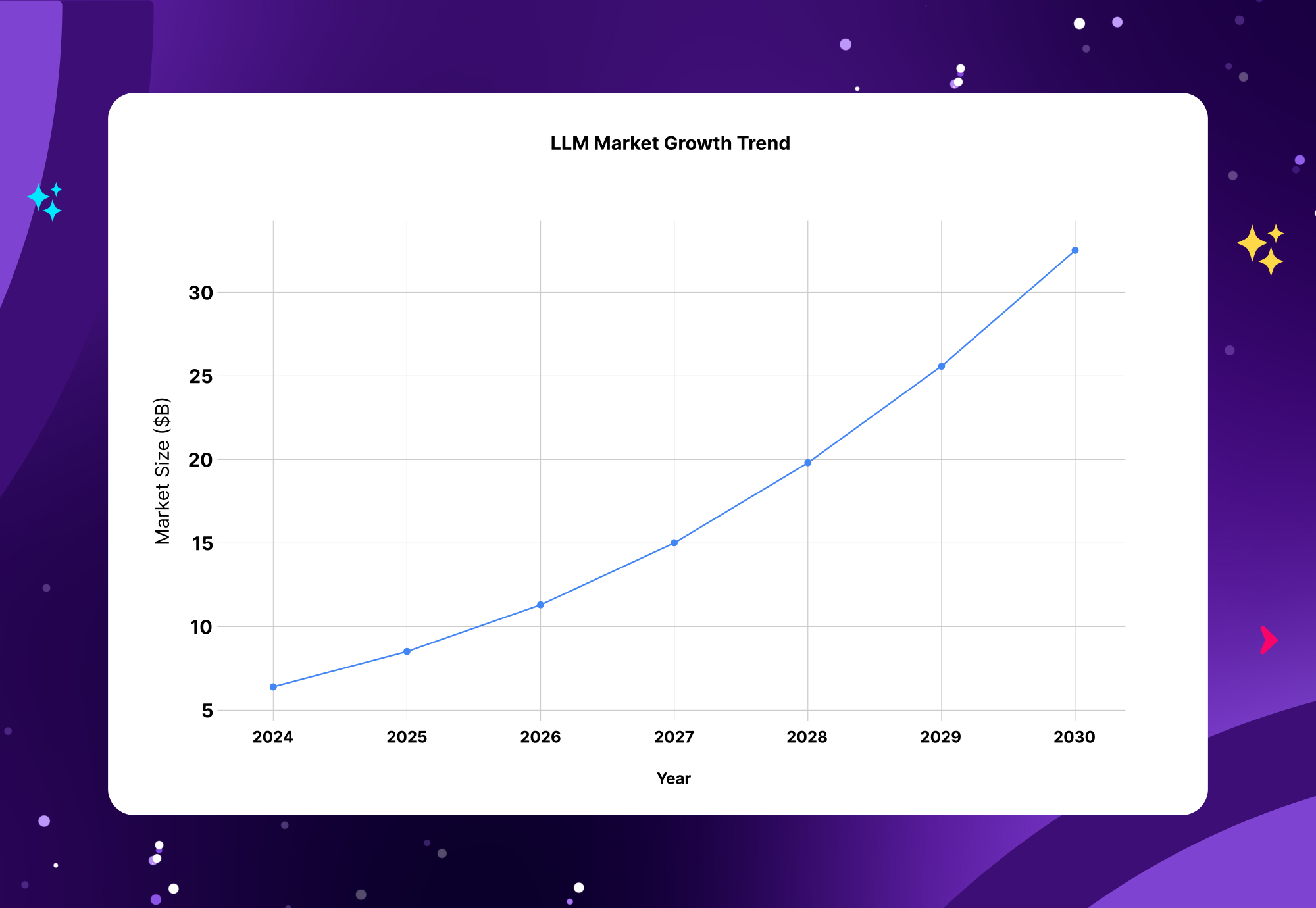
The global LLM market is projected to grow from USD 6.4 billion in 2024 to USD 36.1 billion by 2030, reflecting a CAGR of 33.2%. This rapid expansion shows the accelerating adoption of LLMs across industries.
North America is expected to be the largest regional market due to strong tech presence and infrastructure, with Asia Pacific as the fastest-growing region because of linguistic diversity and emerging AI startups.
Compute and Training Trends
The computational resources used for training leading AI models have increased exponentially, with training compute growing by approximately 4-5x per year over recent years
This massive increase in compute power has been crucial for improving LLM performance and scale.
Adoption and Usage Trends
As of 2024, 78% of organizations use AI in at least one business function, with generative AI—including LLMs—adopted by 71% of enterprises.
Enterprise spending on LLMs is expected to accelerate, with many organizations increasing budgets to leverage AI capabilities
Model Size Trends
LLMs have grown from billions to trillions of parameters, with dramatic increases in parameter counts over a short period, enabling more complex language understanding.
Why Partner with Trantor for Your LLM Journey
At Trantor, we bring enterprise-grade capabilities across data engineering, machine learning, AI operations and cloud infrastructure. Whether you’re just at the planning phase or already collecting domain-specific data and need to scale to production, we can support you.
- Capabilities in end-to-end LLM build: data processing, tokenisation pipelines, model fine-tuning.
- Integration expertise: connecting models into enterprise workflows, CRMs, chatbots, analytics platforms.
- Governance and compliance: helping you build secure, auditable, scalable AI systems aligned with your business risk posture.
- Global team of 1000+ professionals with deep experience in digital transformation and software delivery.











