AI, zBlog
What is Retrieval Augmented Generation (RAG)?

Introduction
As we stride into the year 2024, the field of artificial intelligence (AI) and natural language processing (NLP) is witnessing a paradigm shift fueled by the rapid advancement of large language models (LLMs). These powerful models, capable of generating human-like text across a wide range of applications, have opened up new frontiers in the realm of language understanding and generation.
However, despite their impressive capabilities, LLMs face a significant challenge: their knowledge is limited to what they were trained on, which can become outdated or incomplete as new information emerges. This is where Retrieval Augmented Generation (RAG) comes into play, promising to revolutionize the way LLMs operate and expand their knowledge horizons.
What is Retrieval Augmented Generation(RAG)?
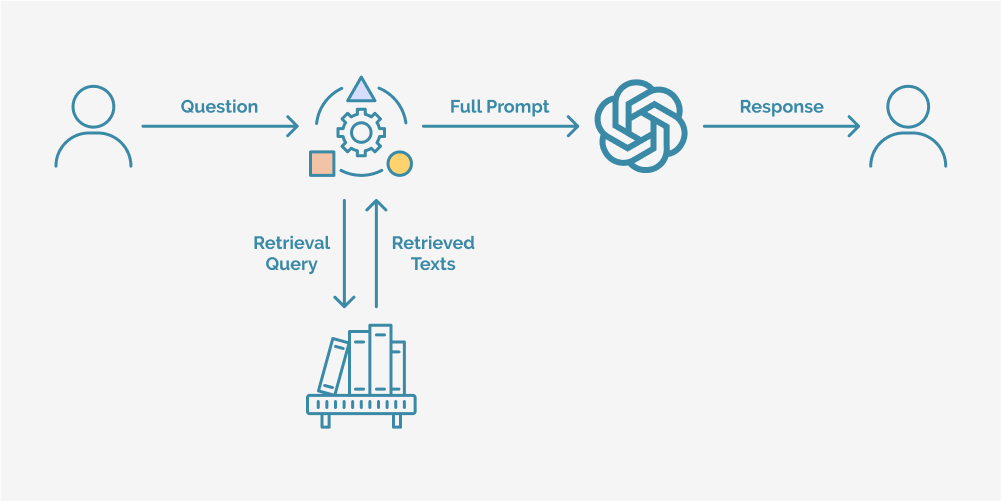
Retrieval Augmented Generation (RAG) is a cutting-edge approach that combines the power of large language models with the vast knowledge available in external corpora, such as the internet or domain-specific databases. By integrating a retrieval system with a generative language model, RAG enables LLMs to dynamically access and incorporate relevant information from these external sources during the generation process.
The fundamental idea behind RAG is to augment the knowledge and capabilities of LLMs by leveraging retrieval systems that can quickly identify and fetch relevant information from vast data repositories. This retrieved information is then provided as additional context to the language model, allowing it to generate more informed and up-to-date responses while still leveraging its inherent language understanding and generation abilities.
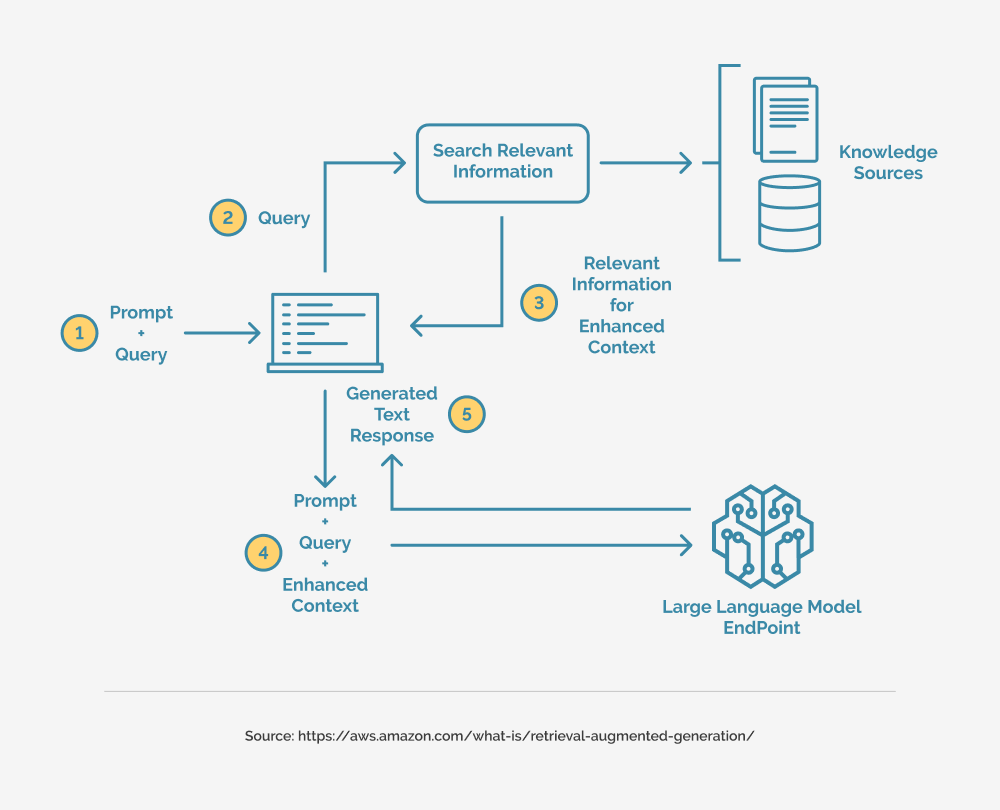
The RAG Workflow:
- Query Understanding: The first step in the Retrieval Augmented Generation process is to analyze the input query or prompt using the language model’s inherent understanding capabilities. This analysis helps identify the key concepts, entities, and information needed to generate an appropriate response.
- Retrieval: Based on the analysis of the query, the retrieval system searches through the external corpus or knowledge base to identify and fetch relevant documents, passages, or data points that may provide additional context or information to address the query.
- Context Integration: The retrieved information is then integrated with the original query or prompt, forming a contextualized input that combines the user’s intent with the relevant external knowledge.
- Generation: The contextualized input is fed into the language model, which leverages its generative capabilities to produce a response that incorporates both its own knowledge and the retrieved external information.
- Iterative Refinement: In some cases, the generated response may trigger additional retrieval and generation cycles, allowing the Retrieval Augmented Generation system to iteratively refine and improve its output based on the newly retrieved information.
The Power of RAG in 2024

As we move deeper into 2024, Retrieval Augmented Generation is poised to become a game-changer in the field of LLMs, unlocking new possibilities and addressing critical limitations. Here are some key advantages and applications of RAG that will shape the future of LLMs:
- Knowledge Expansion: By tapping into external knowledge sources, RAG enables LLMs to expand their knowledge horizons beyond their initial training data. This means that LLMs can stay up-to-date with the latest information, trends, and developments, ensuring their responses remain relevant and accurate over time.
- Domain Adaptation: RAG allows LLMs to adapt to specific domains or subject areas by leveraging domain-specific corpora or knowledge bases. This versatility makes RAG invaluable for applications ranging from scientific research and medical diagnosis to legal analysis and technical support.
- Fact-checking and Verification: With the ability to retrieve and cross-reference information from authoritative sources, RAG can enhance the factual accuracy and trustworthiness of LLM-generated outputs, mitigating the risk of spreading misinformation or inaccuracies.
- Personalized Interactions: By incorporating user-specific information or preferences from external sources, RAG can enable more personalized and tailored interactions with LLMs, enhancing the user experience and delivering more relevant and contextualized responses.
- Explainable AI: RAG can contribute to the interpretability and explainability of LLM outputs by providing transparency into the external sources and information used during the generation process, fostering trust and understanding in AI systems.
- Multimodal Integration: As RAG evolves, it has the potential to integrate with multimodal retrieval systems, allowing LLMs to leverage and reason over various types of data, such as images, videos, and structured data, opening up new avenues for rich and multimodal language generation.
Challenges and Future Directions

While RAG presents numerous opportunities and advantages, it also introduces several challenges that must be addressed to fully unlock its potential:
- Efficient Retrieval: Developing efficient and scalable retrieval systems capable of quickly identifying and fetching relevant information from vast and diverse data sources is a significant challenge, particularly in real-time applications or scenarios with high query volumes.
- Information Quality and Trustworthiness: Ensuring the quality and trustworthiness of the retrieved information is crucial, as inaccurate or low-quality data can lead to misleading or unreliable LLM outputs. Robust filtering, verification, and ranking mechanisms are essential to mitigate this risk.
- Context Integration and Coherence: Seamlessly integrating the retrieved information into the generative process while maintaining coherence, consistency, and natural language flow is a non-trivial task that requires advanced techniques and careful design.
- Multimodal Reasoning: As RAG expands to incorporate multimodal data, developing LLMs capable of reasoning over and integrating information from diverse modalities (text, images, videos, etc.) will be a significant challenge, requiring advancements in multimodal representation learning and cross-modal reasoning.
- Ethical Considerations: With the ability to access and incorporate vast amounts of external information, RAG systems must be designed with robust ethical safeguards to address issues such as privacy, bias, and the potential misuse or spread of harmful or illegal content.
- Scalability and Computational Efficiency: As the scale and complexity of LLMs and external corpora continue to grow, ensuring the scalability and computational efficiency of RAG systems will be crucial for practical and widespread adoption.
Despite these challenges, the future of RAG is promising, with ongoing research and development efforts aimed at addressing these issues and unlocking the full potential of this transformative approach.
Trantor: Pioneering the Future of RAG
At Trantor, we are at the forefront of innovation in Artificial Intelligence and natural language processing. Our team of experts is dedicated to pushing the boundaries of Retrieval Augmented Generation (RAG) and exploring its vast potential in powering the future of LLMs.
With our deep expertise in cutting-edge technologies and a commitment to delivering cutting-edge solutions, we are well-positioned to help organizations harness the power of RAG and unlock new possibilities in language understanding, generation, and knowledge integration.
By partnering with Trantor, you gain access to our state-of-the-art RAG systems, tailored to your specific needs and requirements. Whether you seek to expand your LLM’s knowledge horizons, adapt to specialized domains, or enhance the accuracy and trustworthiness of your language generation capabilities, our team will work closely with you to develop innovative RAG solutions that drive your success.
At Trantor, we believe in the transformative potential of RAG, and we are committed to staying at the forefront of this rapidly evolving field. Join us on this exciting journey as we shape the future of LLMs and unlock new frontiers in language understanding and generation.











